 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Pass Transformer for Machine Translation
Paper and Code
Sep 23, 2020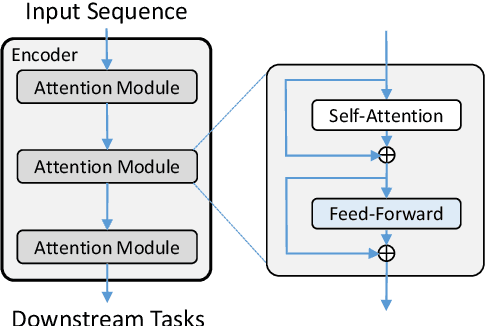
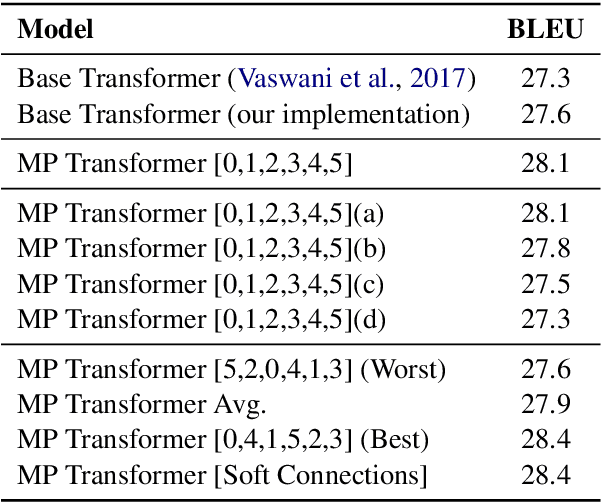
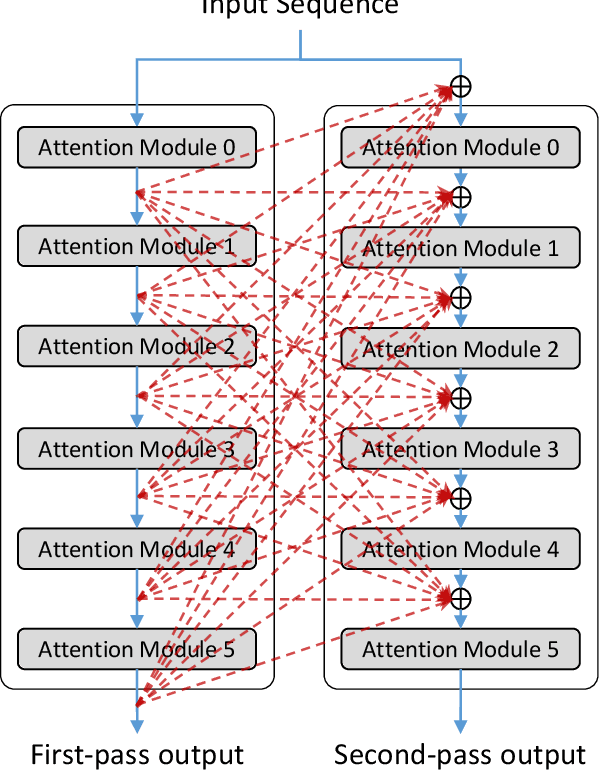
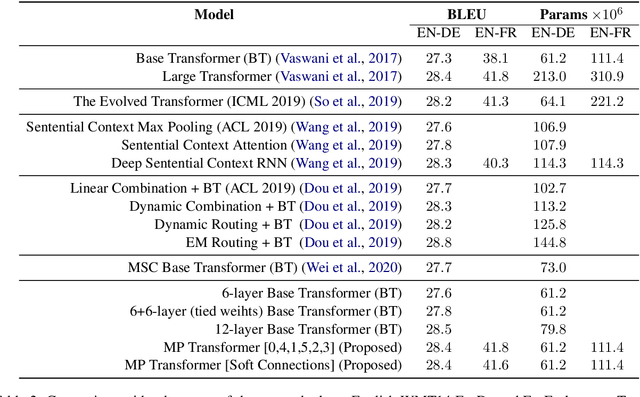
In contrast with previous approaches where information flows only towards deeper layers of a stack, we consider a multi-pass transformer (MPT) architecture in which earlier layers are allowed to process information in light of the output of later layers. To maintain a directed acyclic graph structure, the encoder stack of a transformer is repeated along a new multi-pass dimension, keeping the parameters tied, and information is allowed to proceed unidirectionally both towards deeper layers within an encoder stack and towards any layer of subsequent stacks. We consider both soft (i.e., continuous) and hard (i.e., discrete) connections between parallel encoder stacks, relying on a neural architecture search to find the best connection pattern in the hard case. We perform an extensive ablation study of the proposed MPT architecture and compare it with other state-of-the-art transformer architectures. Surprisingly, Base Transformer equipped with MPT can surpass the performance of Large Transformer on the challenging machine translation En-De and En-Fr datasets. In the hard connection case, the optimal connection pattern found for En-De also leads to improved performance for En-Fr.