 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionStitching: Boosting Memory Intensive Computations for Deep Learning Workloads
Paper and Code
Sep 23, 2020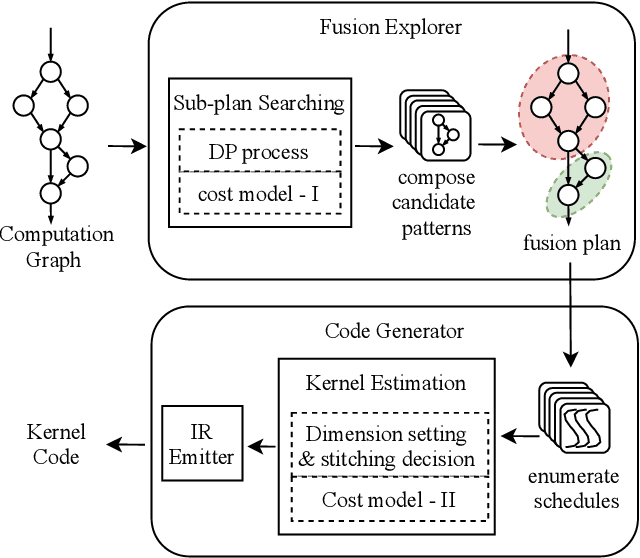
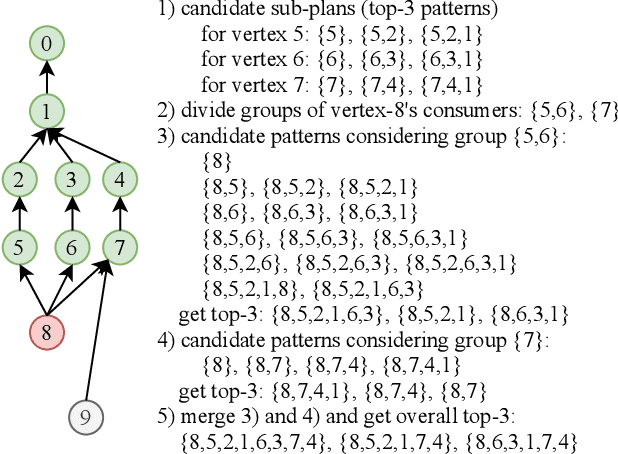
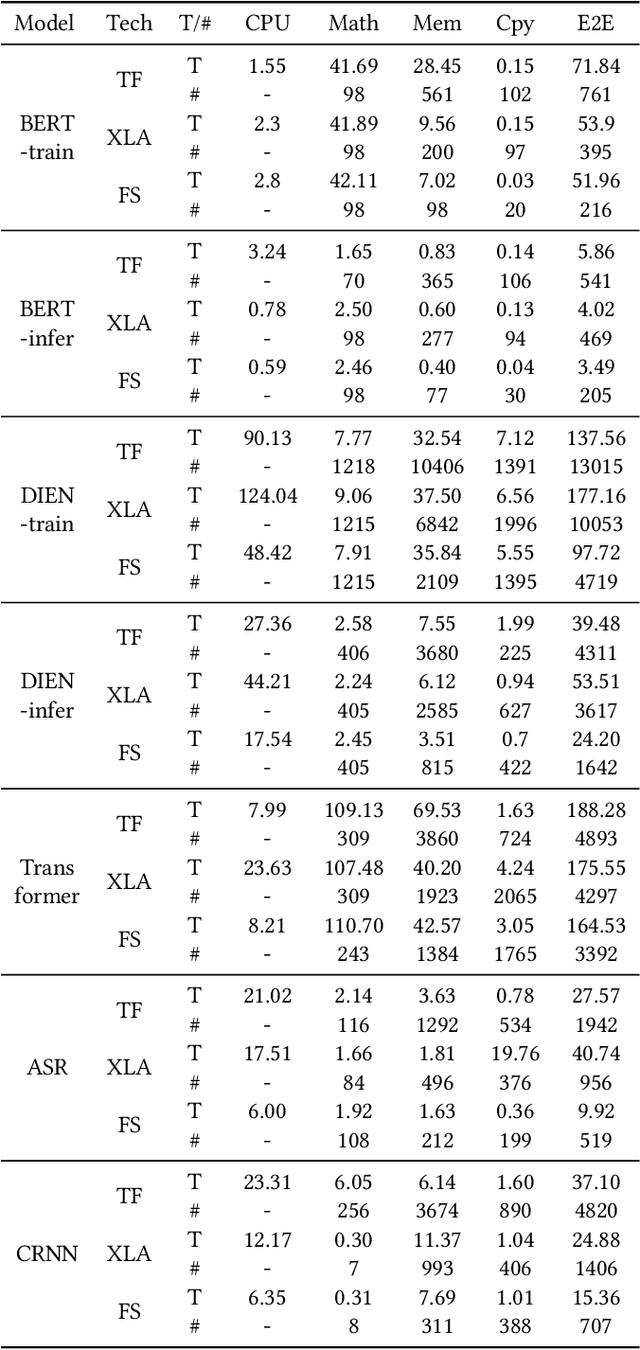
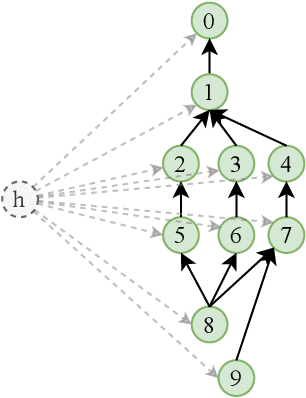
We show in this work that memory intensive computations can result in severe performance problems due to off-chip memory access and CPU-GPU context switch overheads in a wide range of deep learning models. For this problem, current just-in-time kernel fusion and code generation techniques have limitations, such as kernel schedule incompatibilities and rough fusion plan exploration strategies. We propose FusionStitching, a Deep Learning compiler capable of fusing memory intensive operators, with varied data dependencies and non-homogeneous parallelism, into large GPU kernels to reduce global memory access and operation scheduling overhead automatically. FusionStitching explores large fusion spaces to decide optimal fusion plans with considerations of memory access costs, kernel calls and resource usage constraints. We thoroughly study the schemes to stitch operators together for complex scenarios. FusionStitching tunes the optimal stitching scheme just-in-time with a domain-specific cost model efficiently. Experimental results show that FusionStitching can reach up to 2.78x speedup compared to TensorFlow and current state-of-the-art. Besides these experimental results, we integrated our approach into a compiler product and deployed it onto a production cluster for AI workloads with thousands of GPUs. The system has been in operation for more than 4 months and saves 7,000 GPU hours on average for approximately 30,000 tasks per month.