 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Robustness and Generality of NLP Models Using Disentangled Representations
Paper and Code
Sep 21, 2020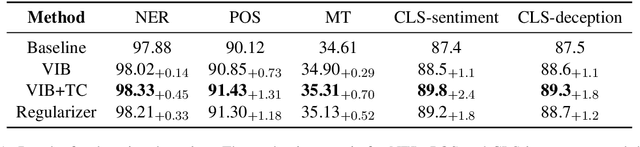
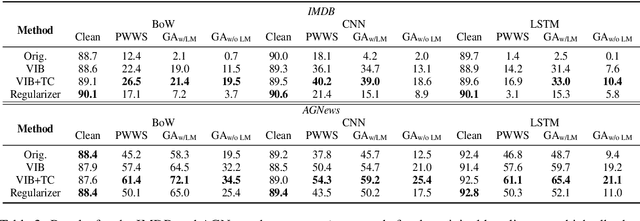
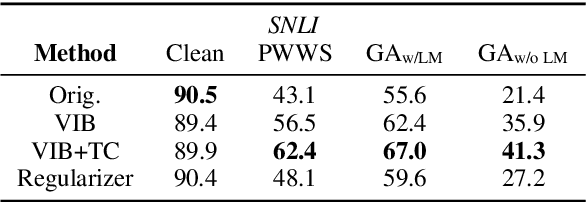
Supervised neural networks, which first map an input $x$ to a single representation $z$, and then map $z$ to the output label $y$, have achieved remarkable success in a wide range of natural language processing (NLP) tasks. Despite their success, neural models lack for both robustness and generality: small perturbations to inputs can result in absolutely different outputs; the performance of a model trained on one domain drops drastically when tested on another domain. In this paper, we present methods to improve robustness and generality of NLP models from the standpoint of disentangled representation learning. Instead of mapping $x$ to a single representation $z$, the proposed strategy maps $x$ to a set of representations $\{z_1,z_2,...,z_K\}$ while forcing them to be disentangled. These representations are then mapped to different logits $l$s, the ensemble of which is used to make the final prediction $y$. We propose different methods to incorporate this idea into currently widely-used models, including adding an $L$2 regularizer on $z$s or adding Total Correlation (TC) under the framework of variational information bottleneck (VIB). We show that models trained with the proposed criteria provide better robustness and domain adaptation ability in a wide range of supervised learning tasks.