 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking Beyond Sentence-Level Natural Language Inference for Downstream Tasks
Paper and Code

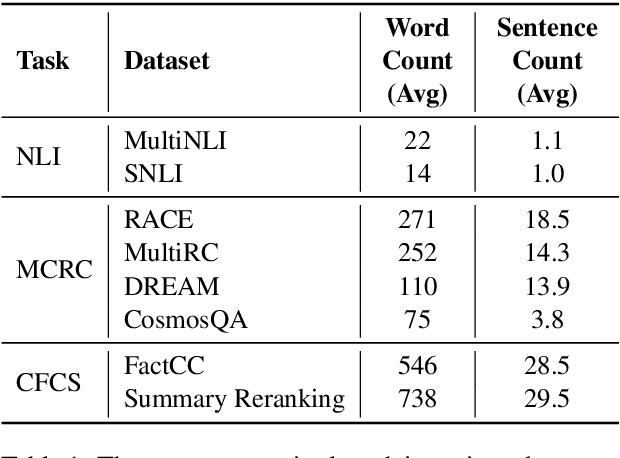
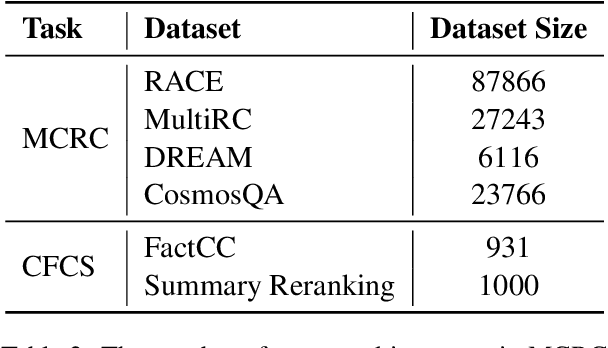
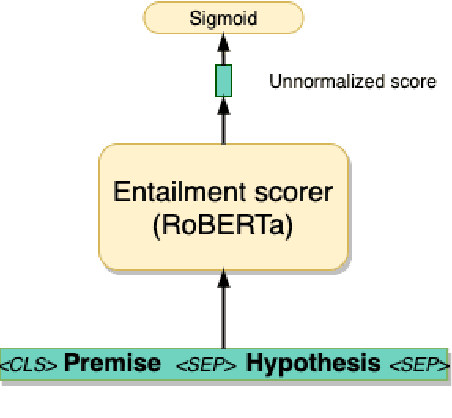
In recent years, the Natural Language Inference (NLI) task has garnered significant attention, with new datasets and models achieving near human-level performance on it. However, the full promise of NLI -- particularly that it learns knowledge that should be generalizable to other downstream NLP tasks -- has not been realized. In this paper, we study this unfulfilled promise from the lens of two downstream tasks: question answering (QA), and text summarization. We conjecture that a key difference between the NLI datasets and these downstream tasks concerns the length of the premise; and that creating new long premise NLI datasets out of existing QA datasets is a promising avenue for training a truly generalizable NLI model. We validate our conjecture by showing competitive results on the task of QA and obtaining the best reported results on the task of Checking Factual Correctness of Summaries.