 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Group Learning
Paper and Code
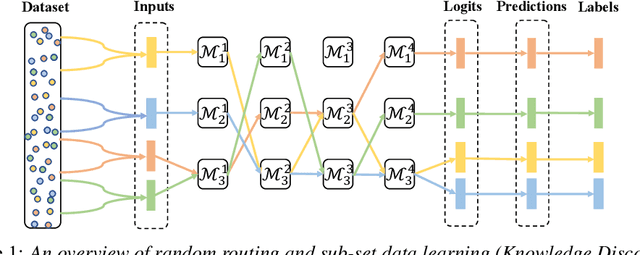
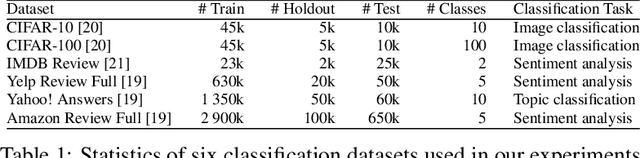


Collaborative learning has successfully applied knowledge transfer to guiding a pool of small student networks towards robust local minima. However, previous approaches typically struggle with drastically aggravated student homogenization and rapidly growing computational complexity when the number of students rises. In this paper, we propose Collaborative Group Learning, an efficient framework that aims to maximize student population without sacrificing generalization performance and computational efficiency. First, each student is established by randomly routing on a modular neural network, which is not only parameter-efficient but also facilitates flexible knowledge communication between students due to random levels of representation sharing and branching. Second, to resist homogenization and further reduce the computational cost, students first compose diverse feature sets by exploiting the inductive bias from sub-sets of training data, and then aggregate and distill supplementary knowledge by choosing a random sub-group of students at each time step. Empirical evaluations on both image and text tasks indicate that our method significantly outperforms various state-of-the-art collaborative approaches whilst enhancing computational efficiency.