 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJob2Vec: Job Title Benchmarking with Collective Multi-View Representation Learning
Paper and Code
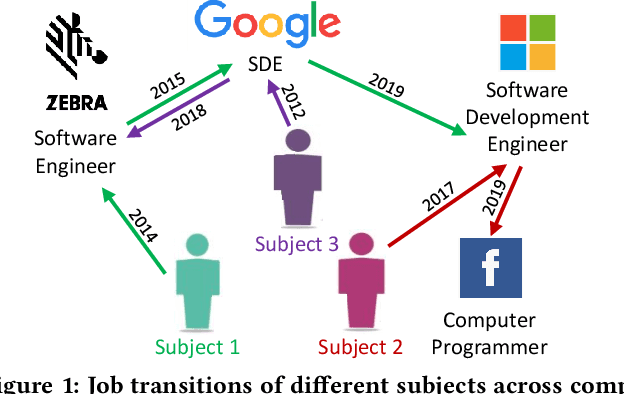

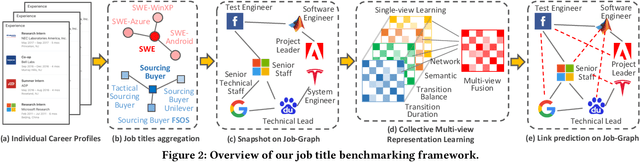
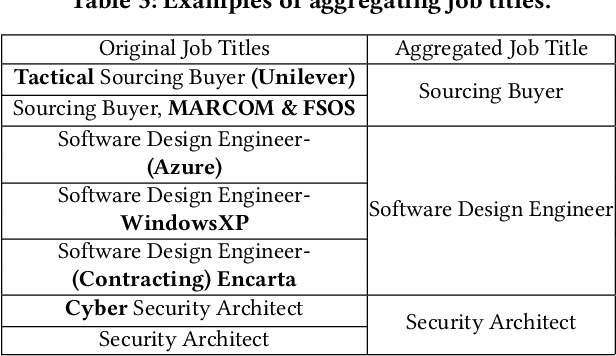
Job Title Benchmarking (JTB) aims at matching job titles with similar expertise levels across various companies. JTB could provide precise guidance and considerable convenience for both talent recruitment and job seekers for position and salary calibration/prediction. Traditional JTB approaches mainly rely on manual market surveys, which is expensive and labor-intensive. Recently, the rapid development of Online Professional Graph has accumulated a large number of talent career records, which provides a promising trend for data-driven solutions. However, it is still a challenging task since (1) the job title and job transition (job-hopping) data is messy which contains a lot of subjective and non-standard naming conventions for the same position (e.g., Programmer, Software Development Engineer, SDE, Implementation Engineer), (2) there is a large amount of missing title/transition information, and (3) one talent only seeks limited numbers of jobs which brings the incompleteness and randomness modeling job transition patterns. To overcome these challenges, we aggregate all the records to construct a large-scale Job Title Benchmarking Graph (Job-Graph), where nodes denote job titles affiliated with specific companies and links denote the correlations between jobs. We reformulate the JTB as the task of link prediction over the Job-Graph that matched job titles should have links. Along this line, we propose a collective multi-view representation learning method (Job2Vec) by examining the Job-Graph jointly in (1) graph topology view, (2)semantic view, (3) job transition balance view, and (4) job transition duration view. We fuse the multi-view representations in the encode-decode paradigm to obtain a unified optimal representation for the task of link prediction. Finally, we conduct extensive experiments to validate the effectiveness of our proposed method.