 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser-Guided Domain Adaptation for Rapid Annotation from User Interactions: A Study on Pathological Liver Segmentation
Paper and Code
Sep 05, 2020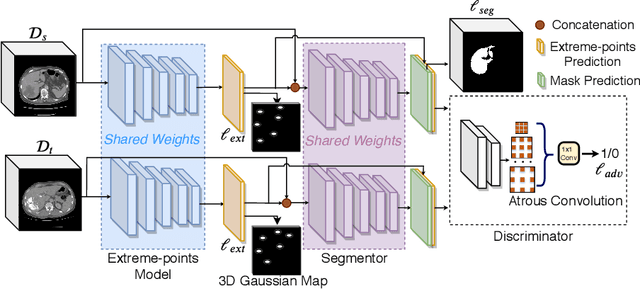
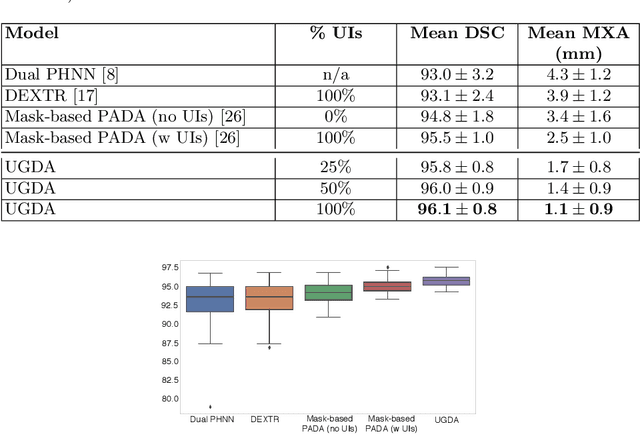


Mask-based annotation of medical images, especially for 3D data, is a bottleneck in developing reliable machine learning models. Using minimal-labor user interactions (UIs) to guide the annotation is promising, but challenges remain on best harmonizing the mask prediction with the UIs. To address this, we propose the user-guided domain adaptation (UGDA) framework, which uses prediction-based adversarial domain adaptation (PADA) to model the combined distribution of UIs and mask predictions. The UIs are then used as anchors to guide and align the mask prediction. Importantly, UGDA can both learn from unlabelled data and also model the high-level semantic meaning behind different UIs. We test UGDA on annotating pathological livers using a clinically comprehensive dataset of 927 patient studies. Using only extreme-point UIs, we achieve a mean (worst-case) performance of 96.1%(94.9%), compared to 93.0% (87.0%) for deep extreme points (DEXTR). Furthermore, we also show UGDA can retain this state-of-the-art performance even when only seeing a fraction of available UIs, demonstrating an ability for robust and reliable UI-guided segmentation with extremely minimal labor demands.