 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoTrans: Automating Transformer Design via Reinforced Architecture Search
Paper and Code
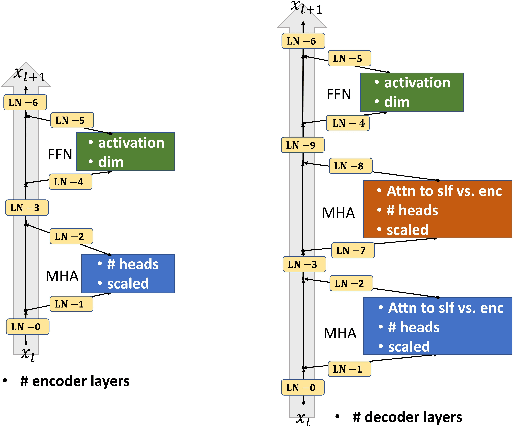

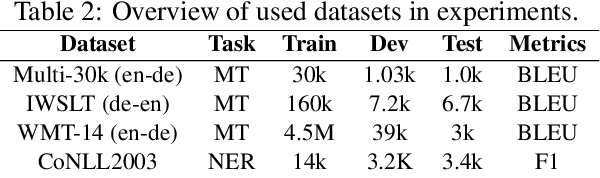
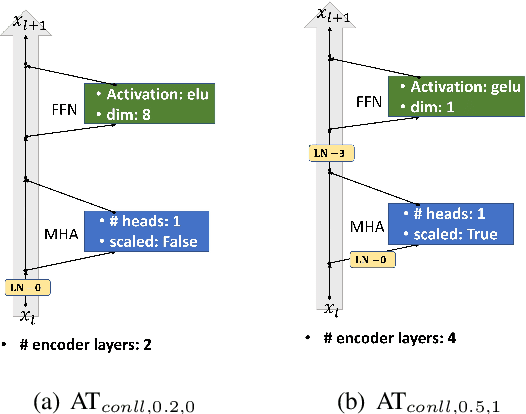
Though the transformer architectures have shown dominance in many natural language understanding tasks, there are still unsolved issues for the training of transformer models, especially the need for a principled way of warm-up which has shown importance for stable training of a transformer, as well as whether the task at hand prefer to scale the attention product or not. In this paper, we empirically explore automating the design choices in the transformer model, i.e., how to set layer-norm, whether to scale, number of layers, number of heads, activation function, etc, so that one can obtain a transformer architecture that better suits the tasks at hand. RL is employed to navigate along search space, and special parameter sharing strategies are designed to accelerate the search. It is shown that sampling a proportion of training data per epoch during search help to improve the search quality. Experiments on the CoNLL03, Multi-30k, IWSLT14 and WMT-14 shows that the searched transformer model can outperform the standard transformers. In particular, we show that our learned model can be trained more robustly with large learning rates without warm-up.