 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Representations of Endoscopic Videos to Detect Tool Presence Without Supervision
Paper and Code

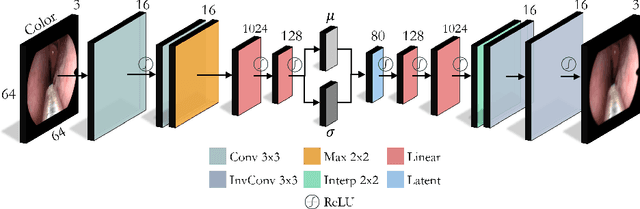
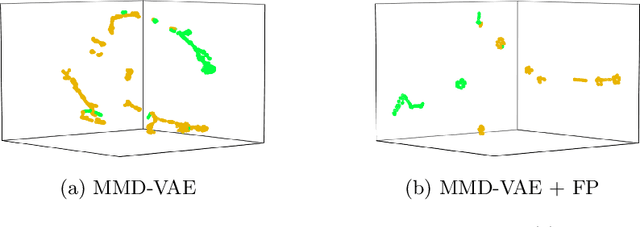
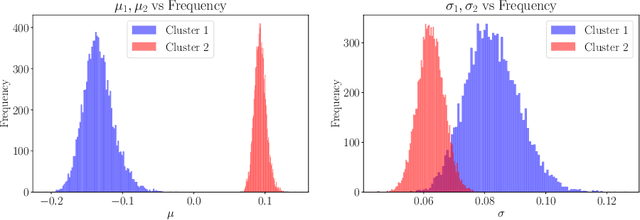
In this work, we explore whether it is possible to learn representations of endoscopic video frames to perform tasks such as identifying surgical tool presence without supervision. We use a maximum mean discrepancy (MMD) variational autoencoder (VAE) to learn low-dimensional latent representations of endoscopic videos and manipulate these representations to distinguish frames containing tools from those without tools. We use three different methods to manipulate these latent representations in order to predict tool presence in each frame. Our fully unsupervised methods can identify whether endoscopic video frames contain tools with average precision of 71.56, 73.93, and 76.18, respectively, comparable to supervised methods. Our code is available at https://github.com/zdavidli/tool-presence/