 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA(DP)$^2$SGD: Asynchronous Decentralized Parallel Stochastic Gradient Descent with Differential Privacy
Paper and Code
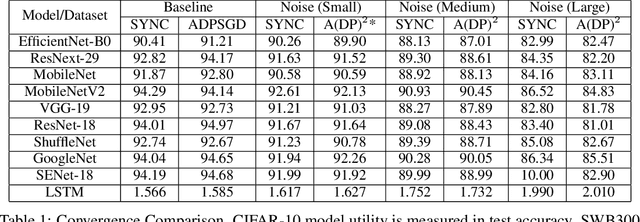
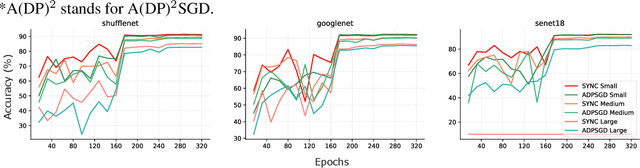
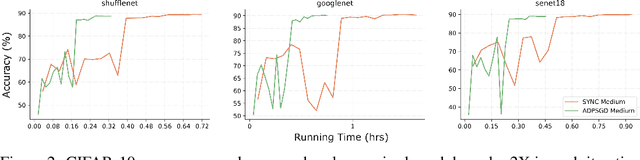
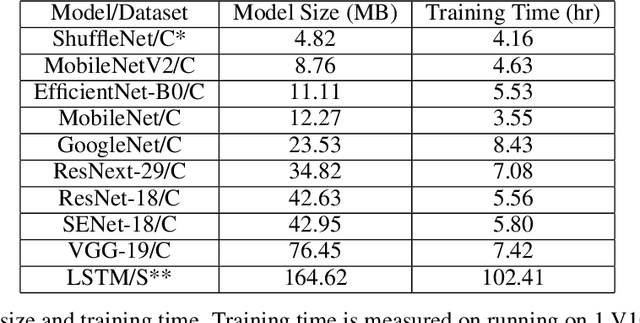
As deep learning models are usually massive and complex, distributed learning is essential for increasing training efficiency. Moreover, in many real-world application scenarios like healthcare, distributed learning can also keep the data local and protect privacy. A popular distributed learning strategy is federated learning, where there is a central server storing the global model and a set of local computing nodes updating the model parameters with their corresponding data. The updated model parameters will be processed and transmitted to the central server, which leads to heavy communication costs. Recently, asynchronous decentralized distributed learning has been proposed and demonstrated to be a more efficient and practical strategy where there is no central server, so that each computing node only communicates with its neighbors. Although no raw data will be transmitted across different local nodes, there is still a risk of information leak during the communication process for malicious participants to make attacks. In this paper, we present a differentially private version of asynchronous decentralized parallel SGD (ADPSGD) framework, or A(DP)$^2$SGD for short, which maintains communication efficiency of ADPSGD and prevents the inference from malicious participants. Specifically, R{\'e}nyi differential privacy is used to provide tighter privacy analysis for our composite Gaussian mechanisms while the convergence rate is consistent with the non-private version. Theoretical analysis shows A(DP)$^2$SGD also converges at the optimal $\mathcal{O}(1/\sqrt{T})$ rate as SGD. Empirically, A(DP)$^2$SGD achieves comparable model accuracy as the differentially private version of Synchronous SGD (SSGD) but runs much faster than SSGD in heterogeneous computing environments.