 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDF-GAN: Deep Fusion Generative Adversarial Networks for Text-to-Image Synthesis
Paper and Code
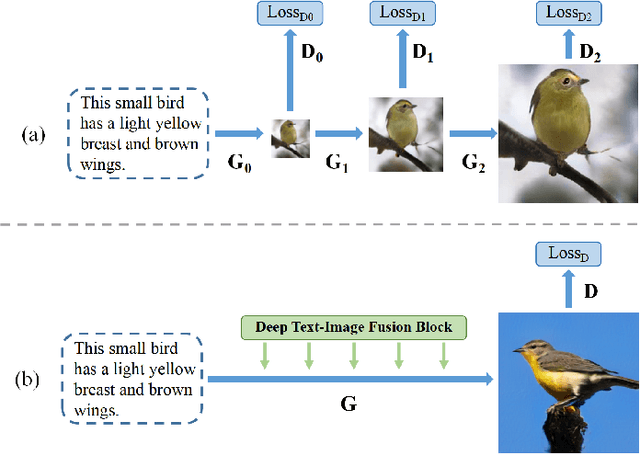

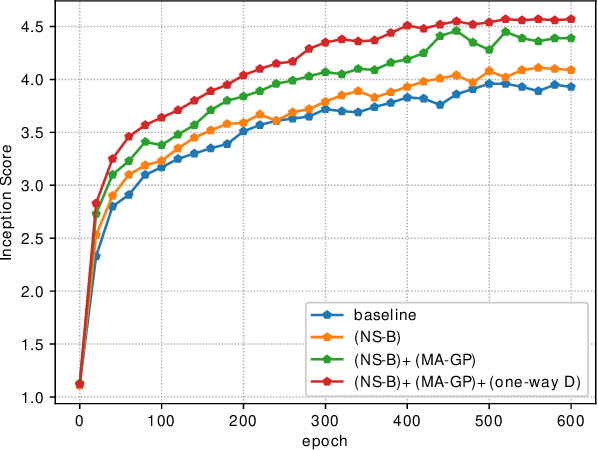
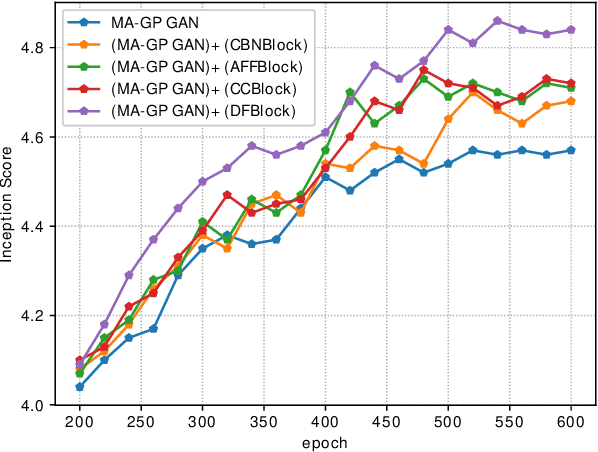
Synthesizing high-resolution realistic images from text descriptions is a challenging task. Almost all existing text-to-image methods employ stacked generative adversarial networks as the backbone, utilize cross-modal attention mechanisms to fuse text and image features, and use extra networks to ensure text-image semantic consistency. The existing text-to-image models have three problems: 1) For the backbone, there are multiple generators and discriminators stacked for generating different scales of images making the training process slow and inefficient. 2) For semantic consistency, the existing models employ extra networks to ensure the semantic consistency increasing the training complexity and bringing an additional computational cost. 3) For the text-image feature fusion method, cross-modal attention is only applied a few times during the generation process due to its computational cost impeding fusing the text and image features deeply. To solve these limitations, we propose 1) a novel simplified text-to-image backbone which is able to synthesize high-quality images directly by one pair of generator and discriminator, 2) a novel regularization method called Matching-Aware zero-centered Gradient Penalty which promotes the generator to synthesize more realistic and text-image semantic consistent images without introducing extra networks, 3) a novel fusion module called Deep Text-Image Fusion Block which can exploit the semantics of text descriptions effectively and fuse text and image features deeply during the generation process. Compared with the previous text-to-image models, our DF-GAN is simpler and more efficient and achieves better performance. Extensive experiments and ablation studies on both Caltech-UCSD Birds 200 and COCO datasets demonstrate the superiority of the proposed model in comparison to state-of-the-art models.