 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Encoding for Video Retrieval with Contrastive Learning
Paper and Code
Aug 04, 2020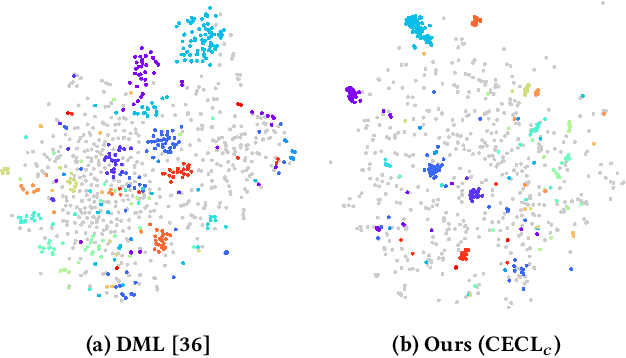
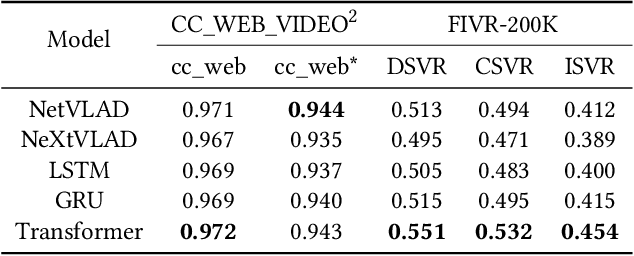
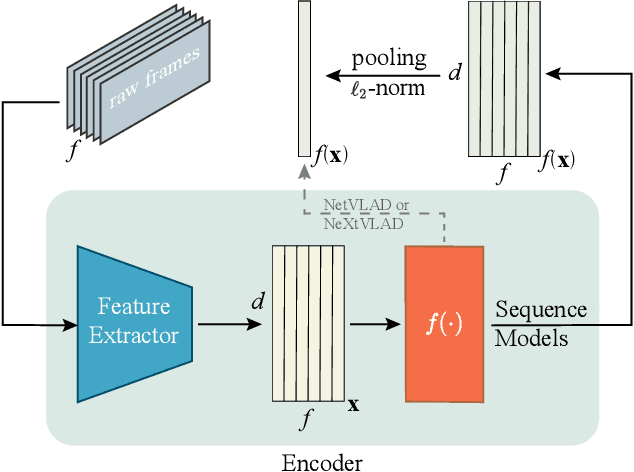

Content-based video retrieval plays an important role in areas such as video recommendation, copyright protection, etc. Existing video retrieval methods mainly extract frame-level features independently, therefore lack of efficient aggregation of features between frames, and it is difficult to effectively deal with poor quality frames, such as frames with motion blur, out of focus, etc. In this paper, we propose CECL (Context Encoding for video retrieval with Contrastive Learning), a video representation learning framework that aggregates the context information of frame-level descriptors, and a supervised contrastive learning method that performs automatic hard negative mining, and utilizes the memory bank mechanism to increase the capacity of negative samples. Extensive experiments are conducted on multi video retrieval tasks, such as FIVR, CC_WEB_VIDEO and EVVE. The proposed method shows a significant performance advantage (~17% mAP on FIVR-200K) over state-of-the-art methods with video-level features, and deliver competitive results with much lower computational cost when compared with frame-level features.