 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Optimizing Preprocessing and Inference for DNN-based Visual Analytics
Paper and Code
Jul 25, 2020
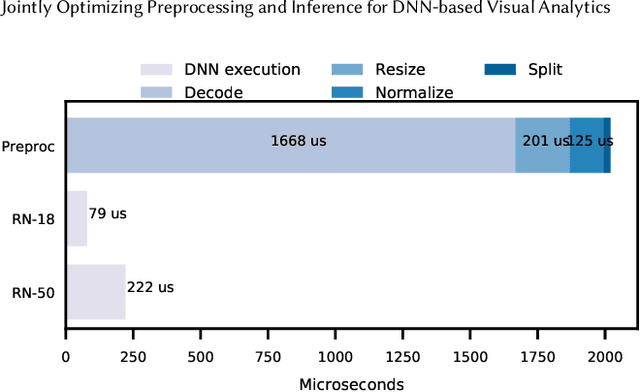


While deep neural networks (DNNs) are an increasingly popular way to query large corpora of data, their significant runtime remains an active area of research. As a result, researchers have proposed systems and optimizations to reduce these costs by allowing users to trade off accuracy and speed. In this work, we examine end-to-end DNN execution in visual analytics systems on modern accelerators. Through a novel measurement study, we show that the preprocessing of data (e.g., decoding, resizing) can be the bottleneck in many visual analytics systems on modern hardware. To address the bottleneck of preprocessing, we introduce two optimizations for end-to-end visual analytics systems. First, we introduce novel methods of achieving accuracy and throughput trade-offs by using natively present, low-resolution visual data. Second, we develop a runtime engine for efficient visual DNN inference. This runtime engine a) efficiently pipelines preprocessing and DNN execution for inference, b) places preprocessing operations on the CPU or GPU in a hardware- and input-aware manner, and c) efficiently manages memory and threading for high throughput execution. We implement these optimizations in a novel system, Smol, and evaluate Smol on eight visual datasets. We show that its optimizations can achieve up to 5.9x end-to-end throughput improvements at a fixed accuracy over recent work in visual analytics.