 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on Evaluation Standard for Automatic Crack Detection Regard the Random Fractal
Paper and Code
Jul 23, 2020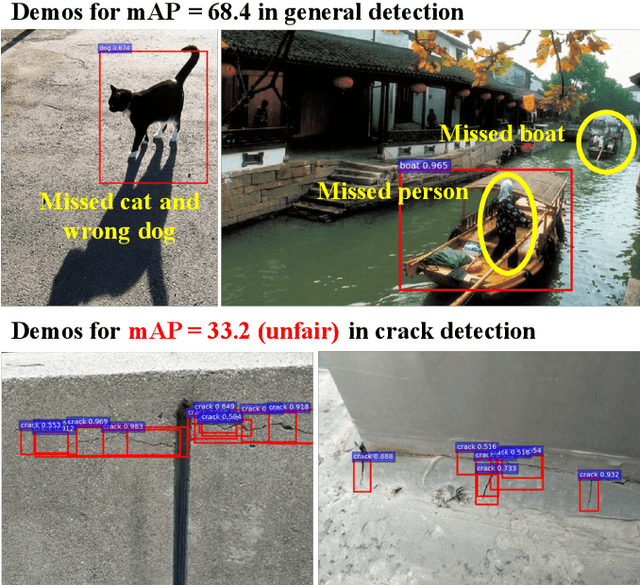

A reasonable evaluation standard underlies construction of effective deep learning models. However, we find in experiments that the automatic crack detectors based on deep learning are obviously underestimated by the widely used mean Average Precision (mAP) standard. This paper presents a study on the evaluation standard. It is clarified that the random fractal of crack disables the mAP standard, because the strict box matching in mAP calculation is unreasonable for the fractal feature. As a solution, a fractal-available evaluation standard named CovEval is proposed to correct the underestimation in crack detection. In CovEval, a different matching process based on the idea of covering box matching is adopted for this issue. In detail, Cover Area rate (CAr) is designed as a covering overlap, and a multi-match strategy is employed to release the one-to-one matching restriction in mAP. Extended Recall (XR), Extended Precision (XP) and Extended F-score (Fext) are defined for scoring the crack detectors. In experiments using several common frameworks for object detection, models get much higher scores in crack detection according to CovEval, which matches better with the visual performance. Moreover, based on faster R-CNN framework, we present a case study to optimize a crack detector based on CovEval standard. Recall (XR) of our best model achieves an industrial-level at 95.8, which implies that with reasonable standard for evaluation, the methods for object detection are with great potential for automatic industrial inspection.