 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep multi-metric learning for text-independent speaker verification
Paper and Code
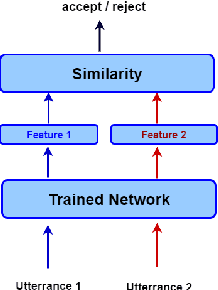

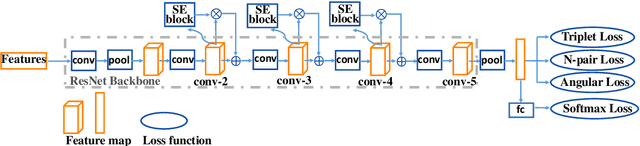

Text-independent speaker verification is an important artificial intelligence problem that has a wide spectrum of applications, such as criminal investigation, payment certification, and interest-based customer services. The purpose of text-independent speaker verification is to determine whether two given uncontrolled utterances originate from the same speaker or not. Extracting speech features for each speaker using deep neural networks is a promising direction to explore and a straightforward solution is to train the discriminative feature extraction network by using a metric learning loss function. However, a single loss function often has certain limitations. Thus, we use deep multi-metric learning to address the problem and introduce three different losses for this problem, i.e., triplet loss, n-pair loss and angular loss. The three loss functions work in a cooperative way to train a feature extraction network equipped with Residual connections and squeeze-and-excitation attention. We conduct experiments on the large-scale \texttt{VoxCeleb2} dataset, which contains over a million utterances from over $6,000$ speakers, and the proposed deep neural network obtains an equal error rate of $3.48\%$, which is a very competitive result. Codes for both training and testing and pretrained models are available at \url{https://github.com/GreatJiweix/DmmlTiSV}, which is the first publicly available code repository for large-scale text-independent speaker verification with performance on par with the state-of-the-art systems.