 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFTRANS: Energy-Efficient Acceleration of Transformers using FPGA
Paper and Code
Jul 16, 2020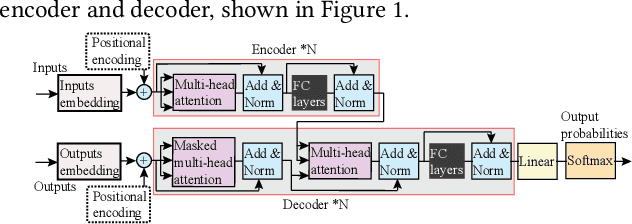

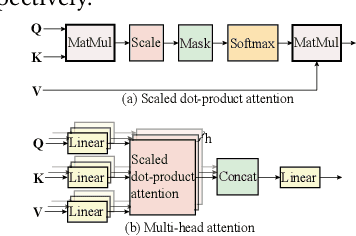
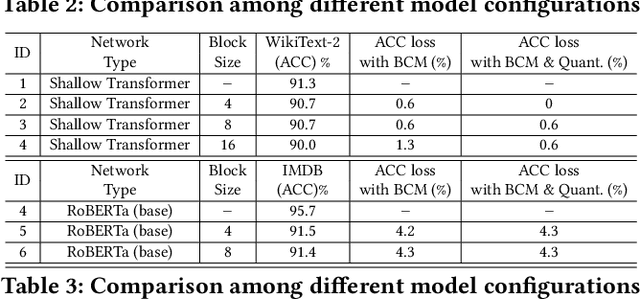
In natural language processing (NLP), the "Transformer" architecture was proposed as the first transduction model replying entirely on self-attention mechanisms without using sequence-aligned recurrent neural networks (RNNs) or convolution, and it achieved significant improvements for sequence to sequence tasks. The introduced intensive computation and storage of these pre-trained language representations has impeded their popularity into computation and memory-constrained devices. The field-programmable gate array (FPGA) is widely used to accelerate deep learning algorithms for its high parallelism and low latency. However, the trained models are still too large to accommodate to an FPGA fabric. In this paper, we propose an efficient acceleration framework, Ftrans, for transformer-based large scale language representations. Our framework includes enhanced block-circulant matrix (BCM)-based weight representation to enable model compression on large-scale language representations at the algorithm level with few accuracy degradation, and an acceleration design at the architecture level. Experimental results show that our proposed framework significantly reduces the model size of NLP models by up to 16 times. Our FPGA design achieves 27.07x and 81x improvement in performance and energy efficiency compared to CPU, and up to 8.80x improvement in energy efficiency compared to GPU.