 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Reinforcement Learning as a Hidden-Parameter Block MDP
Paper and Code
Jul 28, 2020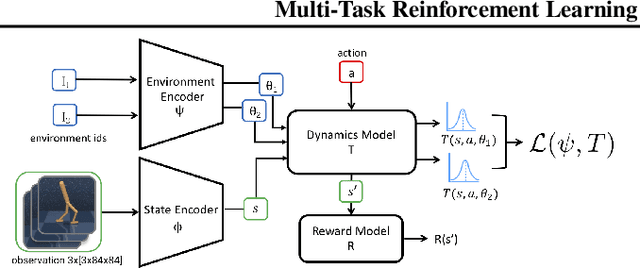
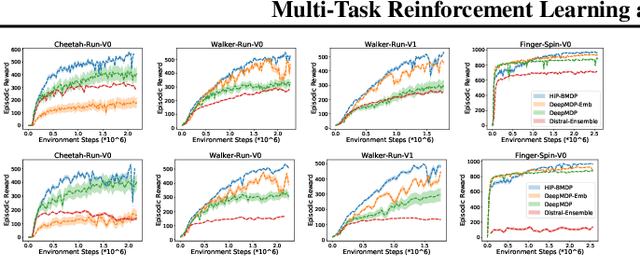
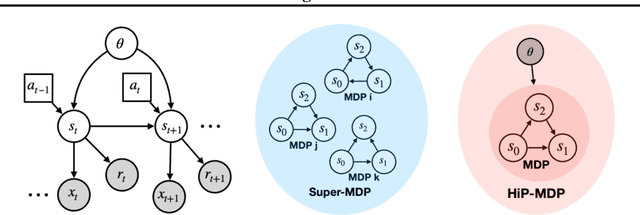

Multi-task reinforcement learning is a rich paradigm where information from previously seen environments can be leveraged for better performance and improved sample-efficiency in new environments. In this work, we leverage ideas of common structure underlying a family of Markov decision processes (MDPs) to improve performance in the few-shot regime. We use assumptions of structure from Hidden-Parameter MDPs and Block MDPs to propose a new framework, HiP-BMDP, and approach for learning a common representation and universal dynamics model. To this end, we provide transfer and generalization bounds based on task and state similarity, along with sample complexity bounds that depend on the aggregate number of samples across tasks, rather than the number of tasks, a significant improvement over prior work. To demonstrate the efficacy of the proposed method, we empirically compare and show improvements against other multi-task and meta-reinforcement learning baselines.