 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based Residual Speech Portrait Model for Speech to Face Generation
Paper and Code
Jul 09, 2020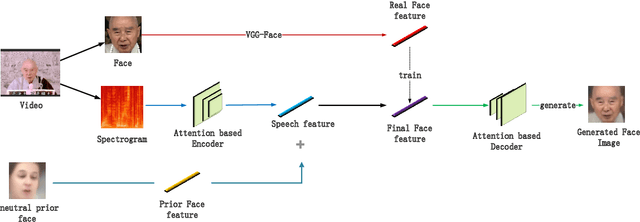

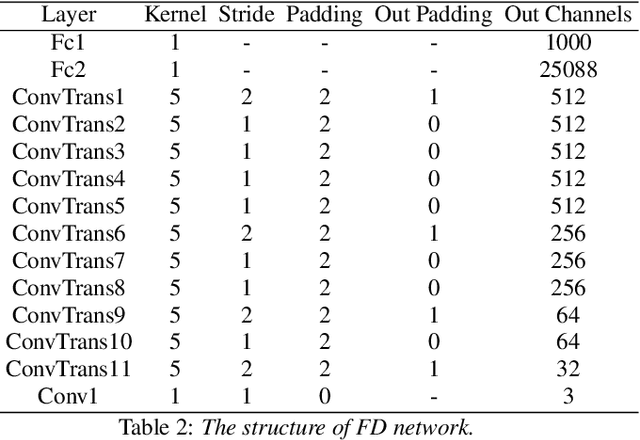

Given a speaker's speech, it is interesting to see if it is possible to generate this speaker's face. One main challenge in this task is to alleviate the natural mismatch between face and speech. To this end, in this paper, we propose a novel Attention-based Residual Speech Portrait Model (AR-SPM) by introducing the ideal of the residual into a hybrid encoder-decoder architecture, where face prior features are merged with the output of speech encoder to form the final face feature. In particular, we innovatively establish a tri-item loss function, which is a weighted linear combination of the L2-norm, L1-norm and negative cosine loss, to train our model by comparing the final face feature and true face feature. Evaluation on AVSpeech dataset shows that our proposed model accelerates the convergence of training, outperforms the state-of-the-art in terms of quality of the generated face, and achieves superior recognition accuracy of gender and age compared with the ground truth.