 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Scene Graphs for Video Dialog
Paper and Code
Jul 08, 2020
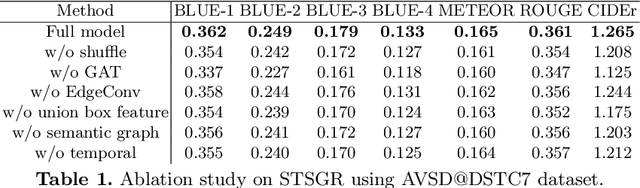
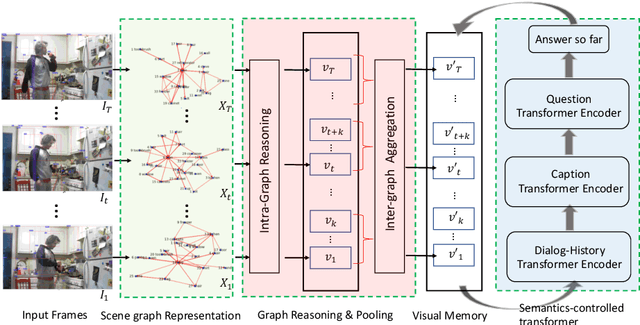
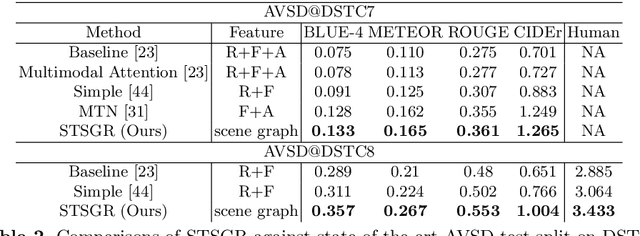
The Audio-Visual Scene-aware Dialog (AVSD) task requires an agent to indulge in a natural conversation with a human about a given video. Specifically, apart from the video frames, the agent receives the audio, brief captions, and a dialog history, and the task is to produce the correct answer to a question about the video. Due to the diversity in the type of inputs, this task poses a very challenging multimodal reasoning problem. Current approaches to AVSD either use global video-level features or those from a few sampled frames, and thus lack the ability to explicitly capture relevant visual regions or their interactions for answer generation. To this end, we propose a novel spatio-temporal scene graph representation (STSGR) modeling fine-grained information flows within videos. Specifically, on an input video sequence, STSGR (i) creates a two-stream visual and semantic scene graph on every frame, (ii) conducts intra-graph reasoning using node and edge convolutions generating visual memories, and (iii) applies inter-graph aggregation to capture their temporal evolutions. These visual memories are then combined with other modalities and the question embeddings using a novel semantics-controlled multi-head shuffled transformer, which then produces the answer recursively. Our entire pipeline is trained end-to-end. We present experiments on the AVSD dataset and demonstrate state-of-the-art results. A human evaluation on the quality of our generated answers shows 12% relative improvement against prior methods.