 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerwise learning for quantum neural networks
Paper and Code
Jun 26, 2020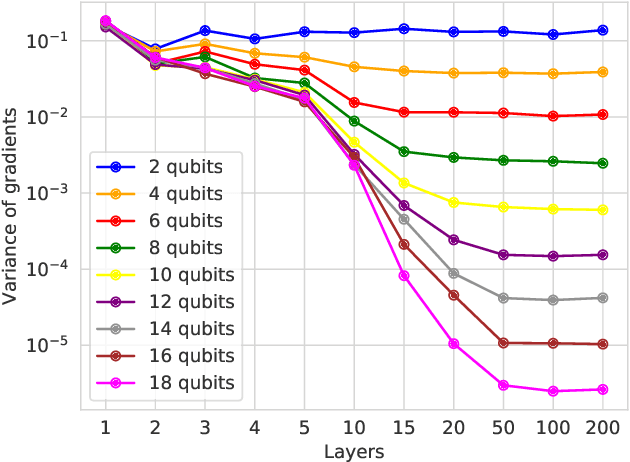
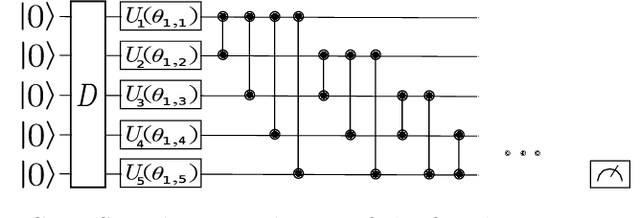
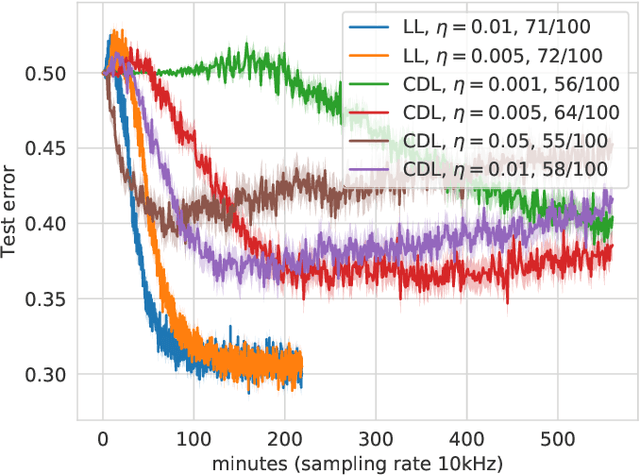
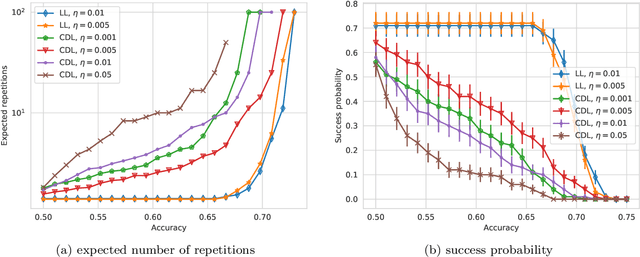
With the increased focus on quantum circuit learning for near-term applications on quantum devices, in conjunction with unique challenges presented by cost function landscapes of parametrized quantum circuits, strategies for effective training are becoming increasingly important. In order to ameliorate some of these challenges, we investigate a layerwise learning strategy for parametrized quantum circuits. The circuit depth is incrementally grown during optimization, and only subsets of parameters are updated in each training step. We show that when considering sampling noise, this strategy can help avoid the problem of barren plateaus of the error surface due to the low depth of circuits, low number of parameters trained in one step, and larger magnitude of gradients compared to training the full circuit. These properties make our algorithm preferable for execution on noisy intermediate-scale quantum devices. We demonstrate our approach on an image-classification task on handwritten digits, and show that layerwise learning attains an 8% lower generalization error on average in comparison to standard learning schemes for training quantum circuits of the same size. Additionally, the percentage of runs that reach lower test errors is up to 40% larger compared to training the full circuit, which is susceptible to creeping onto a plateau during training.