 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Replicability and Reproducibility of Deep Learning in Software Engineering
Paper and Code

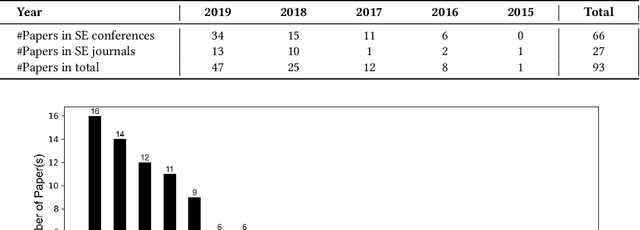
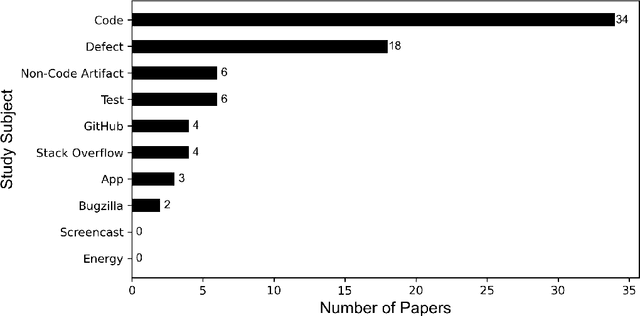
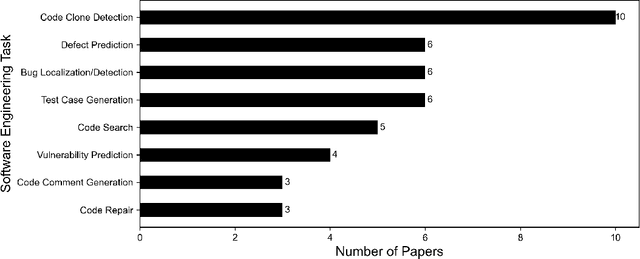
Deep learning (DL) techniques have gained significant popularity among software engineering (SE) researchers in recent years. This is because they can often solve many SE challenges without enormous manual feature engineering effort and complex domain knowledge. Although many DL studies have reported substantial advantages over other state-of-the-art models on effectiveness, they often ignore two factors: (1) replicability - whether the reported experimental result can be approximately reproduced in high probability with the same DL model and the same data; and (2) reproducibility - whether one reported experimental findings can be reproduced by new experiments with the same experimental protocol and DL model, but different sampled real-world data. Unlike traditional machine learning (ML) models, DL studies commonly overlook these two factors and declare them as minor threats or leave them for future work. This is mainly due to high model complexity with many manually set parameters and the time-consuming optimization process. In this study, we conducted a literature review on 93 DL studies recently published in twenty SE journals or conferences. Our statistics show the urgency of investigating these two factors in SE. Moreover, we re-ran four representative DL models in SE. Experimental results show the importance of replicability and reproducibility, where the reported performance of a DL model could not be replicated for an unstable optimization process. Reproducibility could be substantially compromised if the model training is not convergent, or if performance is sensitive to the size of vocabulary and testing data. It is therefore urgent for the SE community to provide a long-lasting link to a replication package, enhance DL-based solution stability and convergence, and avoid performance sensitivity on different sampled data.