 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeak Supervision and Referring Attention for Temporal-Textual Association Learning
Paper and Code
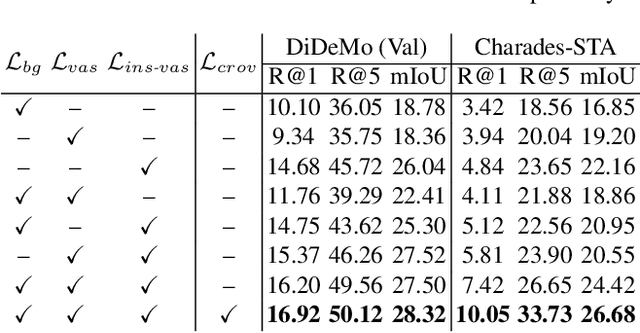
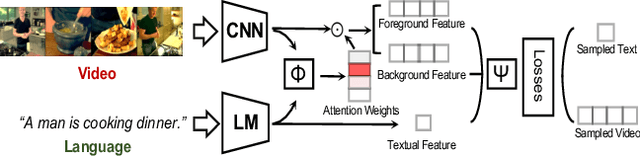
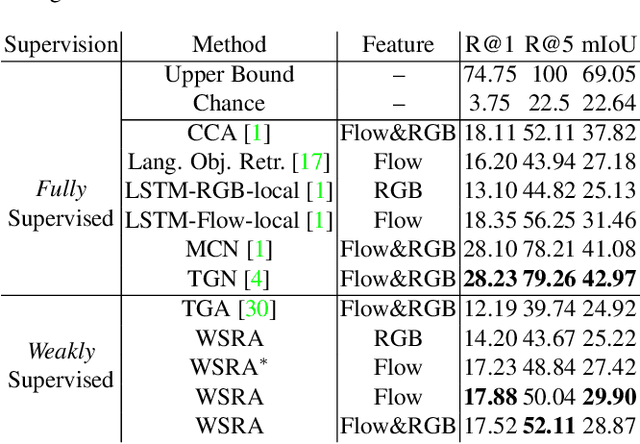
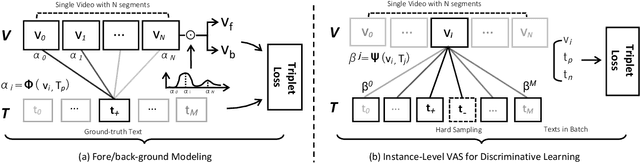
A system capturing the association between video frames and textual queries offer great potential for better video analysis. However, training such a system in a fully supervised way inevitably demands a meticulously curated video dataset with temporal-textual annotations. Therefore we provide a Weak-Supervised alternative with our proposed Referring Attention mechanism to learn temporal-textual association (dubbed WSRA). The weak supervision is simply a textual expression (e.g., short phrases or sentences) at video level, indicating this video contains relevant frames. The referring attention is our designed mechanism acting as a scoring function for grounding the given queries over frames temporally. It consists of multiple novel losses and sampling strategies for better training. The principle in our designed mechanism is to fully exploit 1) the weak supervision by considering informative and discriminative cues from intra-video segments anchored with the textual query, 2) multiple queries compared to the single video, and 3) cross-video visual similarities. We validate our WSRA through extensive experiments for temporally grounding by languages, demonstrating that it outperforms the state-of-the-art weakly-supervised methods notably.