 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocally Differentially Private (Contextual) Bandits Learning
Paper and Code
Jun 01, 2020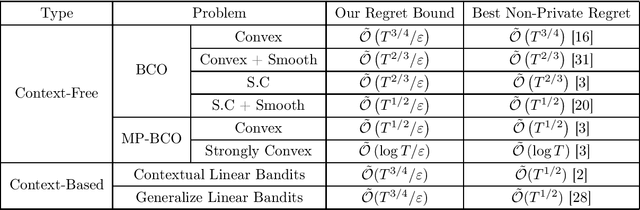
We study locally differentially private (LDP) bandits learning in this paper. First, we propose simple black-box reduction frameworks that can solve a large family of context-free bandits learning problems with LDP guarantee. Based on our frameworks, we can improve previous best results for private bandits learning with one-point feedback, such as private Bandits Convex Optimization etc, and obtain the first results for Bandits Convex Optimization (BCO) with multi-point feedback under LDP. LDP guarantee and black-box nature make our frameworks more attractive in real applications compared with previous specifically designed and relatively weaker differentially private (DP) context-free bandits algorithms. Further, we also extend our algorithm to Generalized Linear Bandits with regret bound $\tilde{\mathcal{O}}(T^{3/4}/\varepsilon)$ under $(\varepsilon, \delta)$-LDP which is conjectured to be optimal. Note given existing $\Omega(T)$ lower bound for DP contextual linear bandits (Shariff&Sheffe,NeurIPS2018), our result shows a fundamental difference between LDP and DP contextual bandits learning.