 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPIN: Structure-Preserving Inner Offset Network for Scene Text Recognition
Paper and Code
May 27, 2020
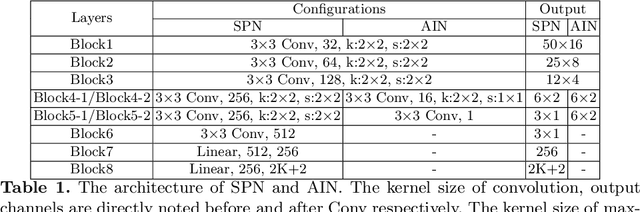
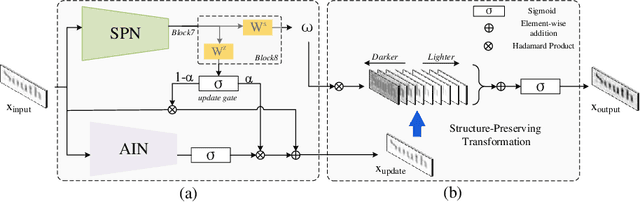
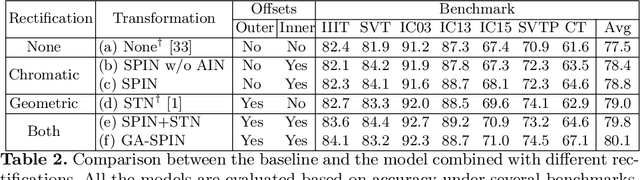
Arbitrary text appearance poses a great challenge in scene text recognition tasks. Existing works mostly handle with the problem in consideration of the shape distortion, including perspective distortions, line curvature or other style variations. Therefore, methods based on spatial transformers are extensively studied. However, chromatic difficulties in complex scenes have not been paid much attention on. In this work, we introduce a new learnable geometric-unrelated module, the Structure-Preserving Inner Offset Network (SPIN), which allows the color manipulation of source data within the network. This differentiable module can be inserted before any recognition architecture to ease the downstream tasks, giving neural networks the ability to actively transform input intensity rather than the existing spatial rectification. It can also serve as a complementary module to known spatial transformations and work in both independent and collaborative ways with them. Extensive experiments show that the use of SPIN results in a significant improvement on multiple text recognition benchmarks compared to the state-of-the-arts.