 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Training for Domain Adaptive Scene Text Detection
Paper and Code
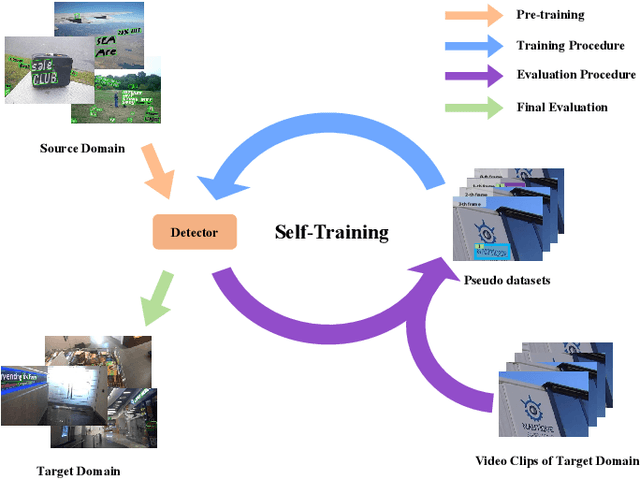
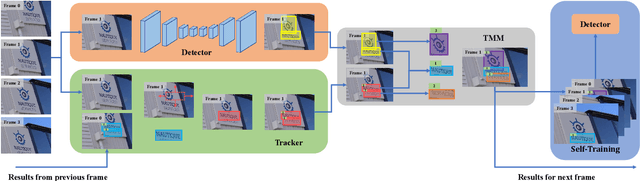
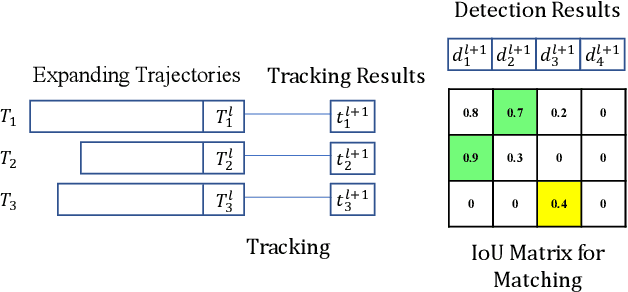

Though deep learning based scene text detection has achieved great progress, well-trained detectors suffer from severe performance degradation for different domains. In general, a tremendous amount of data is indispensable to train the detector in the target domain. However, data collection and annotation are expensive and time-consuming. To address this problem, we propose a self-training framework to automatically mine hard examples with pseudo-labels from unannotated videos or images. To reduce the noise of hard examples, a novel text mining module is implemented based on the fusion of detection and tracking results. Then, an image-to-video generation method is designed for the tasks that videos are unavailable and only images can be used. Experimental results on standard benchmarks, including ICDAR2015, MSRA-TD500, ICDAR2017 MLT, demonstrate the effectiveness of our self-training method. The simple Mask R-CNN adapted with self-training and fine-tuned on real data can achieve comparable or even superior results with the state-of-the-art methods.