 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking the Power of Deep PICO Extraction: Step-wise Medical NER Identification
Paper and Code
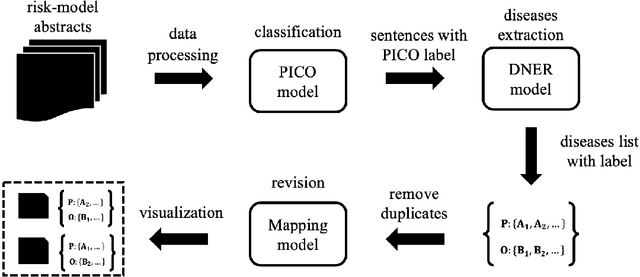



The PICO framework (Population, Intervention, Comparison, and Outcome) is usually used to formulate evidence in the medical domain. The major task of PICO extraction is to extract sentences from medical literature and classify them into each class. However, in most circumstances, there will be more than one evidences in an extracted sentence even it has been categorized to a certain class. In order to address this problem, we propose a step-wise disease Named Entity Recognition (DNER) extraction and PICO identification method. With our method, sentences in paper title and abstract are first classified into different classes of PICO, and medical entities are then identified and classified into P and O. Different kinds of deep learning frameworks are used and experimental results show that our method will achieve high performance and fine-grained extraction results comparing with conventional PICO extraction works.