 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey of Grammar Error Correction
Paper and Code
May 02, 2020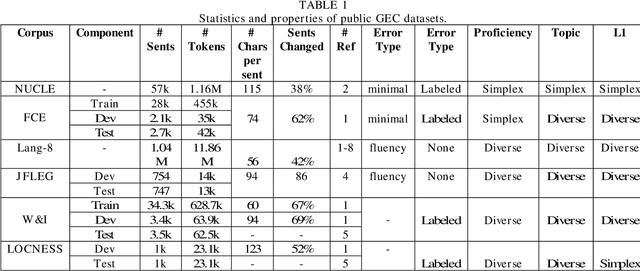
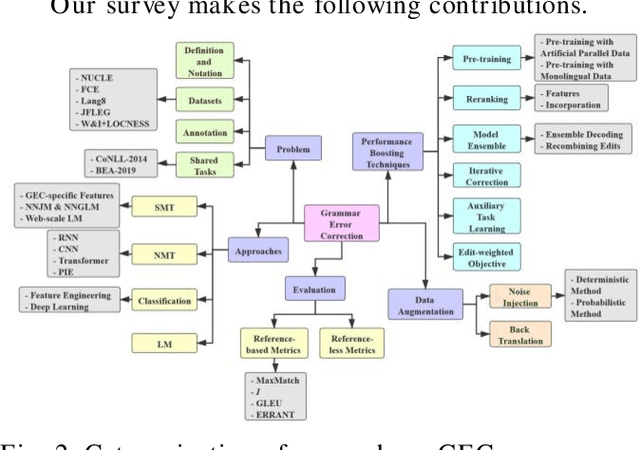
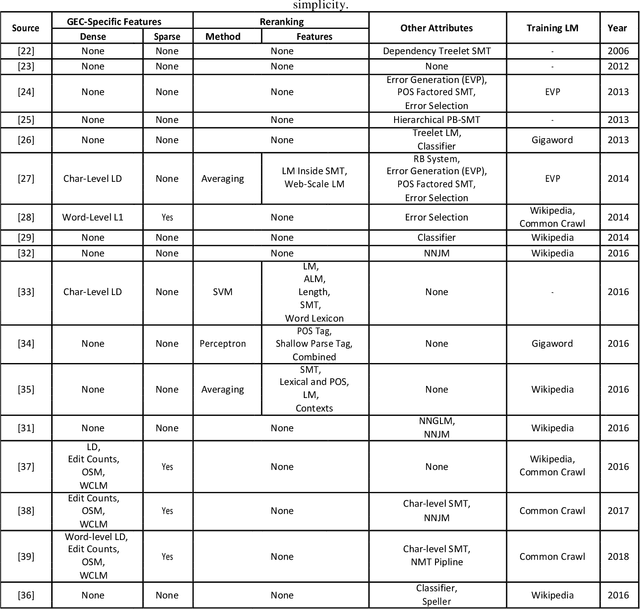

Grammar error correction (GEC) is an important application aspect of natural language processing techniques. The past decade has witnessed significant progress achieved in GEC for the sake of increasing popularity of machine learning and deep learning, especially in late 2010s when near human-level GEC systems are available. However, there is no prior work focusing on the whole recapitulation of the progress. We present the first survey in GEC for a comprehensive retrospect of the literature in this area. We first give the introduction of five public datasets, data annotation schema, two important shared tasks and four standard evaluation metrics. More importantly, we discuss four kinds of basic approaches, including statistical machine translation based approach, neural machine translation based approach, classification based approach and language model based approach, six commonly applied performance boosting techniques for GEC systems and two data augmentation methods. Since GEC is typically viewed as a sister task of machine translation, many GEC systems are based on neural machine translation (NMT) approaches, where the neural sequence-to-sequence model is applied. Similarly, some performance boosting techniques are adapted from machine translation and are successfully combined with GEC systems for enhancement on the final performance. Furthermore, we conduct an analysis in level of basic approaches, performance boosting techniques and integrated GEC systems based on their experiment results respectively for more clear patterns and conclusions. Finally, we discuss five prospective directions for future GEC researches.