 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-To-End Speech Synthesis Applied to Brazilian Portuguese
Paper and Code
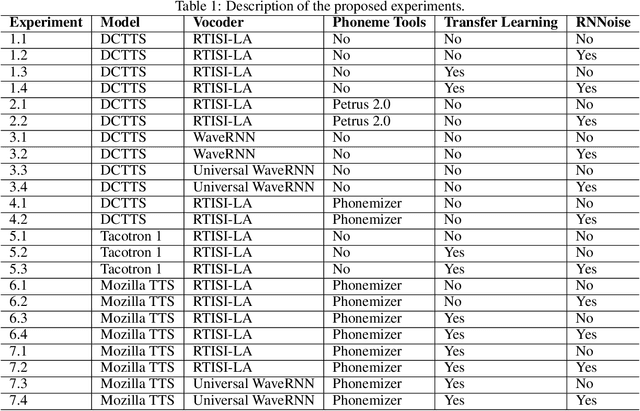
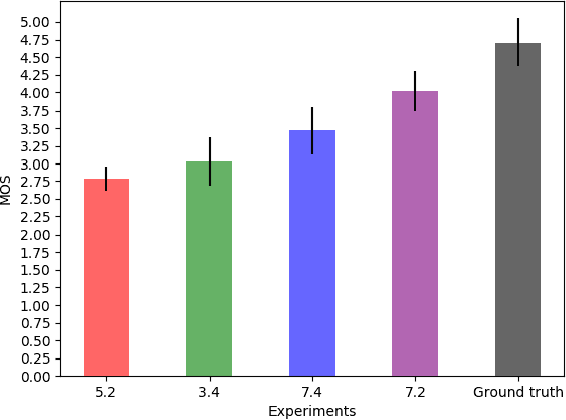

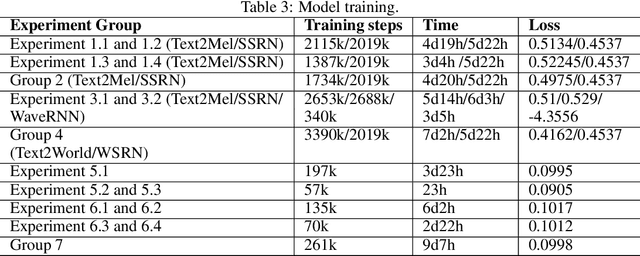
Voice synthesis systems are popular in different applications, such as personal assistants, GPS applications, screen readers and accessibility tools. Voice provides an natural way for human-computer interaction. However, not all languages are in the same level when accounting resources and systems for voice synthesis. This work consists of the creation of publicly available resources for the Brazilian Portuguese language in the form of a dataset and deep learning models for end-to-end voice synthesis. The dataset has 10.5 hours from a single speaker. We investigated three different architectures to perform end-to-end speech synthesis: Tacotron 1, DCTTS and Mozilla TTS. We also analysed the performance of models according to different vocoders (RTISI-LA, WaveRNN and Universal WaveRNN), phonetic transcriptions usage, transfer learning (from English) and denoising. In the proposed scenario, a model based on Mozilla TTS and RTISI-LA vocoder presented the best performance, achieving a 4.03 MOS value. We also verified that transfer learning, phonetic transcriptions and denoising are useful to train the models over the presented dataset. The obtained results are comparable to related works covering English, even using a smaller dataset.