 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascade Attribute Network: Decomposing Reinforcement Learning Control Policies using Hierarchical Neural Networks
Paper and Code
May 07, 2020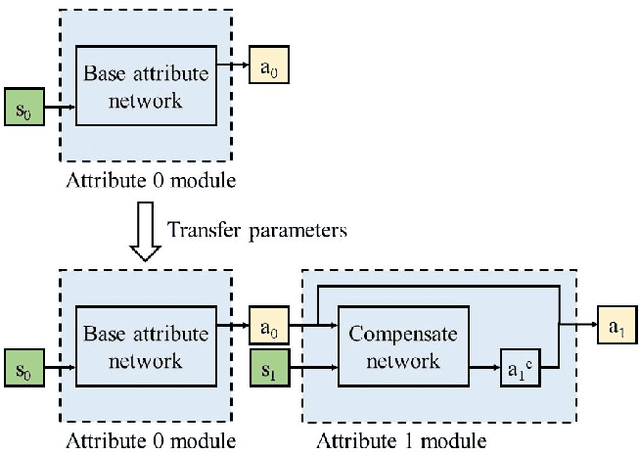
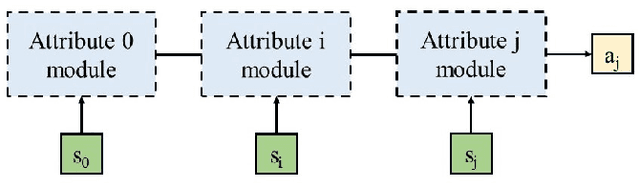

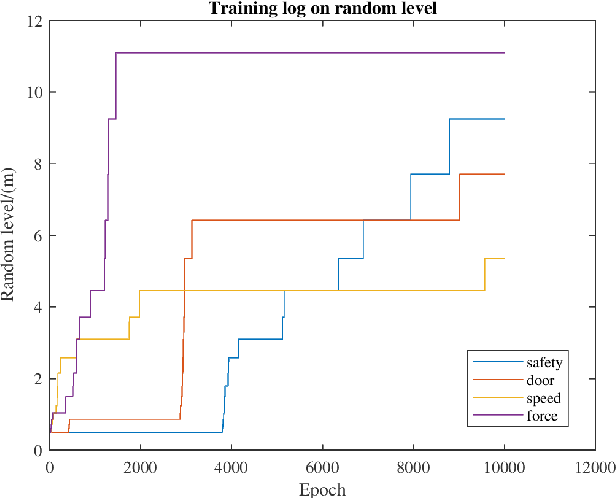
Reinforcement learning methods have been developed to achieve great success in training control policies in various automation tasks. However, a main challenge of the wider application of reinforcement learning in practical automation is that the training process is hard and the pretrained policy networks are hardly reusable in other similar cases. To address this problem, we propose the cascade attribute network (CAN), which utilizes its hierarchical structure to decompose a complicated control policy in terms of the requirement constraints, which we call attributes, encoded in the control tasks. We validated the effectiveness of our proposed method on two robot control scenarios with various add-on attributes. For some control tasks with more than one add-on attribute attribute, by directly assembling the attribute modules in cascade, the CAN can provide ideal control policies in a zero-shot manner.