 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation
Paper and Code


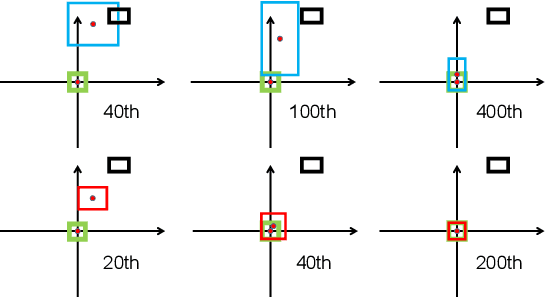
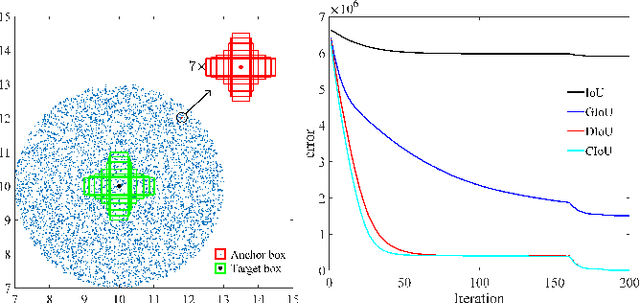
Deep learning-based object detection and instance segmentation have achieved unprecedented progress. In this paper, we propose Complete-IoU (CIoU) loss and Cluster-NMS for enhancing geometric factors in both bounding box regression and Non-Maximum Suppression (NMS), leading to notable gains of average precision (AP) and average recall (AR), without the sacrifice of inference efficiency. In particular, we consider three geometric factors, i.e., overlap area, normalized central point distance and aspect ratio, which are crucial for measuring bounding box regression in object detection and instance segmentation. The three geometric factors are then incorporated into CIoU loss for better distinguishing difficult regression cases. The training of deep models using CIoU loss results in consistent AP and AR improvements in comparison to widely adopted $\ell_n$-norm loss and IoU-based loss. Furthermore, we propose Cluster-NMS, where NMS during inference is done by implicitly clustering detected boxes and usually requires less iterations. Cluster-NMS is very efficient due to its pure GPU implementation, and geometric factors can be incorporated to improve both AP and AR. In the experiments, CIoU loss and Cluster-NMS have been applied to state-of-the-art instance segmentation (e.g., YOLACT), and object detection (e.g., YOLO v3, SSD and Faster R-CNN) models. Taking YOLACT on MS COCO as an example, our method achieves performance gains as +1.7 AP and +6.2 AR$_{100}$ for object detection, and +0.9 AP and +3.5 AR$_{100}$ for instance segmentation, with 27.1 FPS on one NVIDIA GTX 1080Ti GPU. All the source code and trained models are available at https://github.com/Zzh-tju/CIoU