 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan BERT Reason? Logically Equivalent Probes for Evaluating the Inference Capabilities of Language Models
Paper and Code
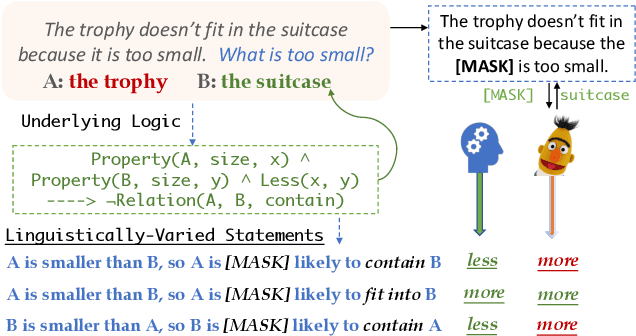

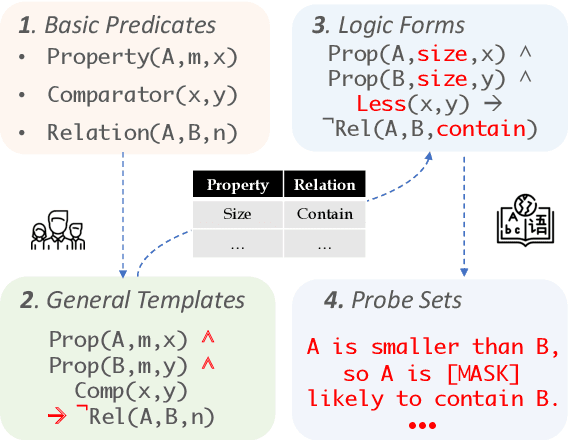

Pre-trained language models (PTLM) have greatly improved performance on commonsense inference benchmarks, however, it remains unclear whether they share a human's ability to consistently make correct inferences under perturbations. Prior studies of PTLMs have found inference deficits, but have failed to provide a systematic means of understanding whether these deficits are due to low inference abilities or poor inference robustness. In this work, we address this gap by developing a procedure that allows for the systematized probing of both PTLMs' inference abilities and robustness. Our procedure centers around the methodical creation of logically-equivalent, but syntactically-different sets of probes, of which we create a corpus of 14,400 probes coming from 60 logically-equivalent sets that can be used to probe PTLMs in three task settings. We find that despite the recent success of large PTLMs on commonsense benchmarks, their performances on our probes are no better than random guessing (even with fine-tuning) and are heavily dependent on biases--the poor overall performance, unfortunately, inhibits us from studying robustness. We hope our approach and initial probe set will assist future work in improving PTLMs' inference abilities, while also providing a probing set to test robustness under several linguistic variations--code and data will be released.