 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantized Adam with Error Feedback
Paper and Code
Apr 29, 2020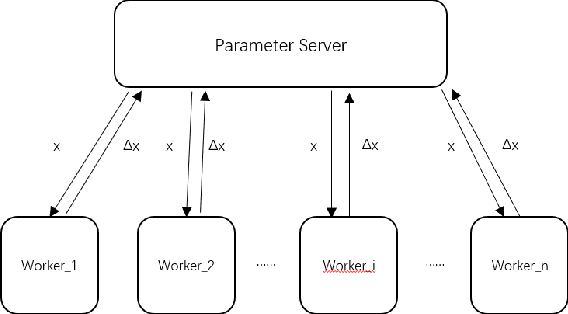
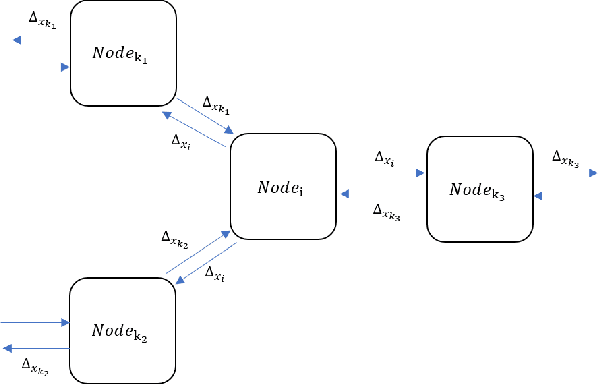
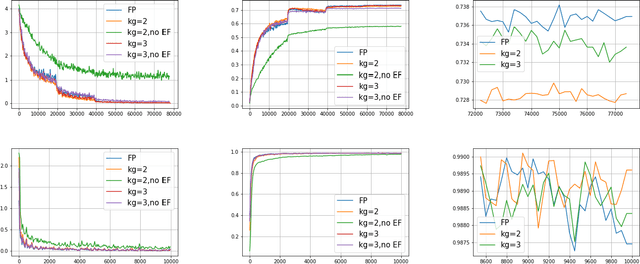
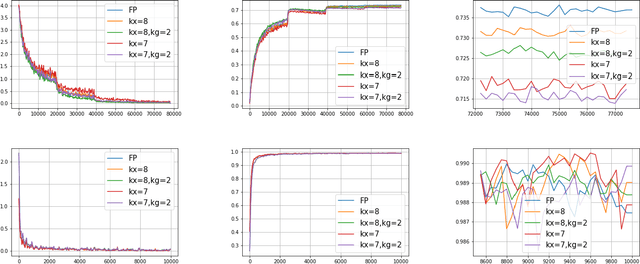
In this paper, we present a distributed variant of adaptive stochastic gradient method for training deep neural networks in the parameter-server model. To reduce the communication cost among the workers and server, we incorporate two types of quantization schemes, i.e., gradient quantization and weight quantization, into the proposed distributed Adam. Besides, to reduce the bias introduced by quantization operations, we propose an error-feedback technique to compensate for the quantized gradient. Theoretically, in the stochastic nonconvex setting, we show that the distributed adaptive gradient method with gradient quantization and error-feedback converges to the first-order stationary point, and that the distributed adaptive gradient method with weight quantization and error-feedback converges to the point related to the quantized level under both the single-worker and multi-worker modes. At last, we apply the proposed distributed adaptive gradient methods to train deep neural networks. Experimental results demonstrate the efficacy of our methods.