 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Attention Attribution: Interpreting Information Interactions Inside Transformer
Paper and Code
Apr 23, 2020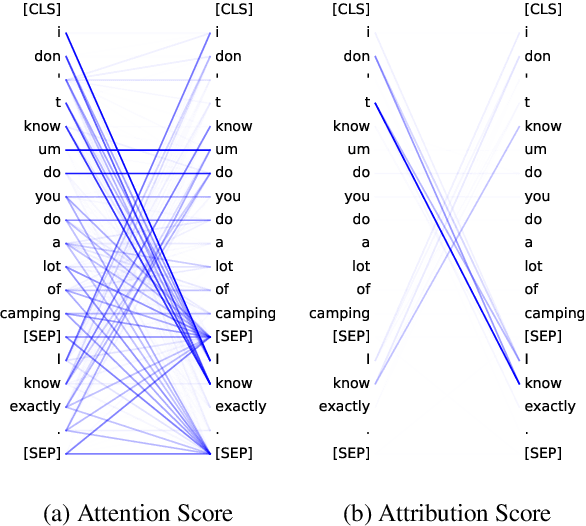
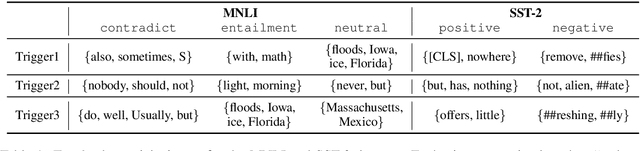
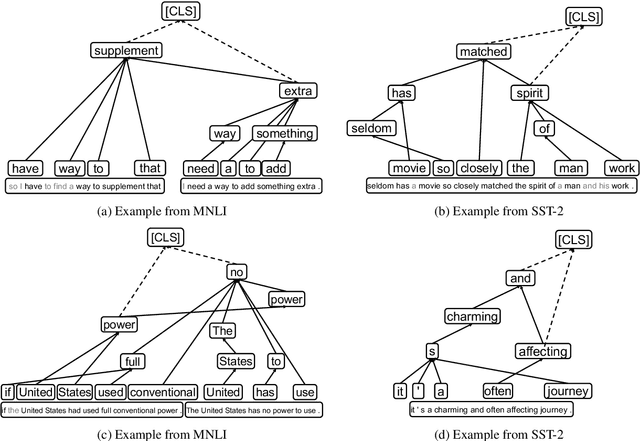
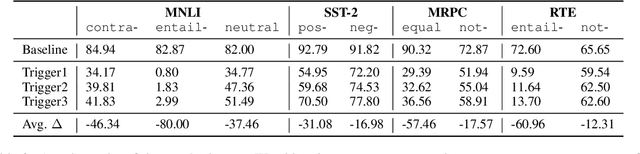
The great success of Transformer-based models benefits from the powerful multi-head self-attention mechanism, which learns token dependencies and encodes contextual information from the input. Prior work strives to attribute model decisions to individual input features with different saliency measures, but they fail to explain how these input features interact with each other to reach predictions. In this paper, we propose a self-attention attribution algorithm to interpret the information interactions inside Transformer. We take BERT as an example to conduct extensive studies. Firstly, we extract the most salient dependencies in each layer to construct an attribution graph, which reveals the hierarchical interactions inside Transformer. Furthermore, we apply self-attention attribution to identify the important attention heads, while others can be pruned with only marginal performance degradation. Finally, we show that the attribution results can be used as adversarial patterns to implement non-targeted attacks towards BERT.