 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Commonsense Graphs: Reasoning about the Dynamic Context of a Still Image
Paper and Code
Apr 22, 2020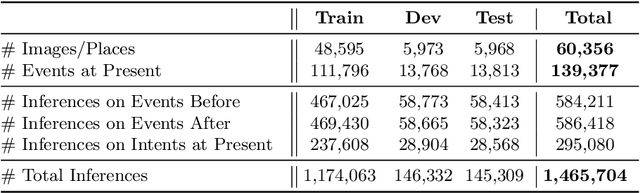
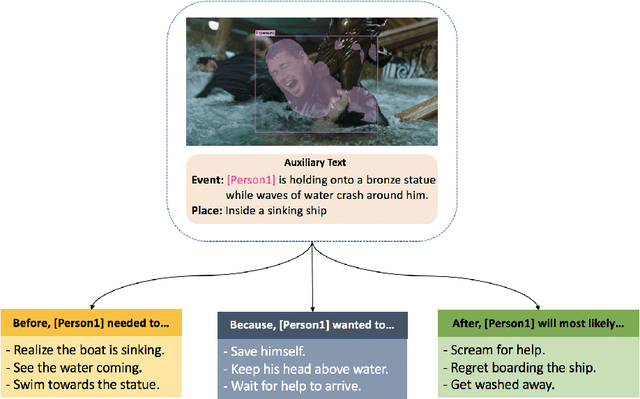
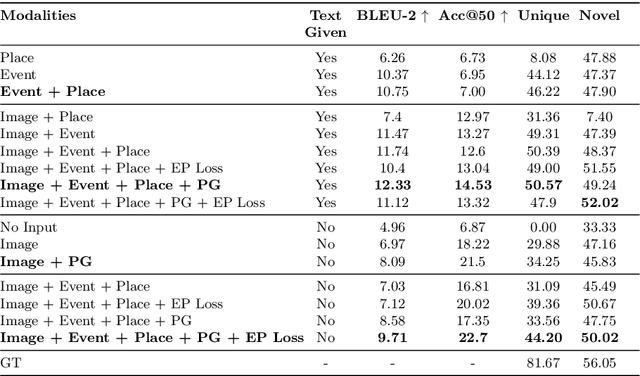

Even from a single frame of a still image, people can reason about the dynamic story of the image before, after, and beyond the frame. For example, given an image of a man struggling to stay afloat in water, we can reason that the man fell into the water sometime in the past, the intent of that man at the moment is to stay alive, and he will need help in the near future or else he will get washed away. We propose VisualComet, the novel framework of visual commonsense reasoning tasks to predict events that might have happened before, events that might happen next, and the intents of the people at present. To support research toward visual commonsense reasoning, we introduce the first large-scale repository of Visual Commonsense Graphs that consists of over 1.4 million textual descriptions of visual commonsense inferences carefully annotated over a diverse set of 60,000 images, each paired with short video summaries of before and after. In addition, we provide person-grounding (i.e., co-reference links) between people appearing in the image and people mentioned in the textual commonsense descriptions, allowing for tighter integration between images and text. We establish strong baseline performances on this task and demonstrate that integration between visual and textual commonsense reasoning is the key and wins over non-integrative alternatives.