 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Multiple Cluster Centers for Multi-Label Learning
Paper and Code
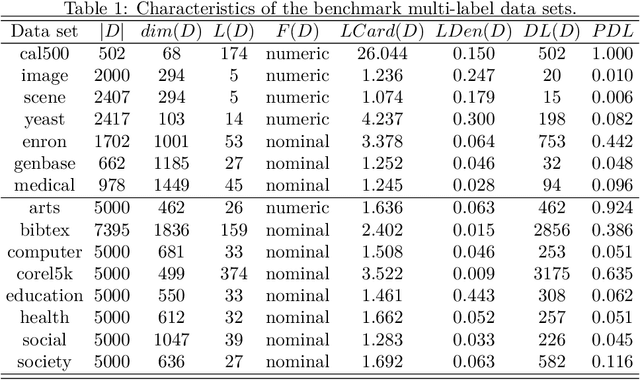
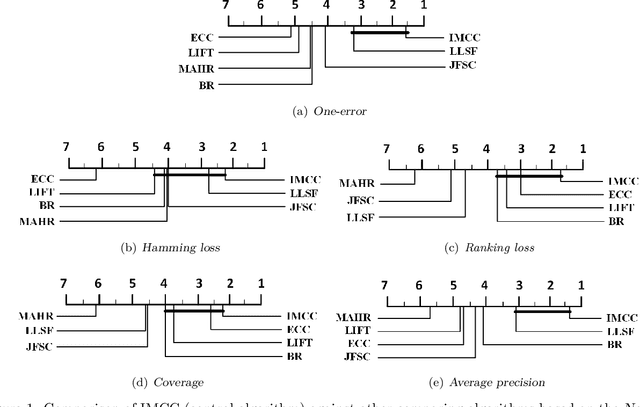
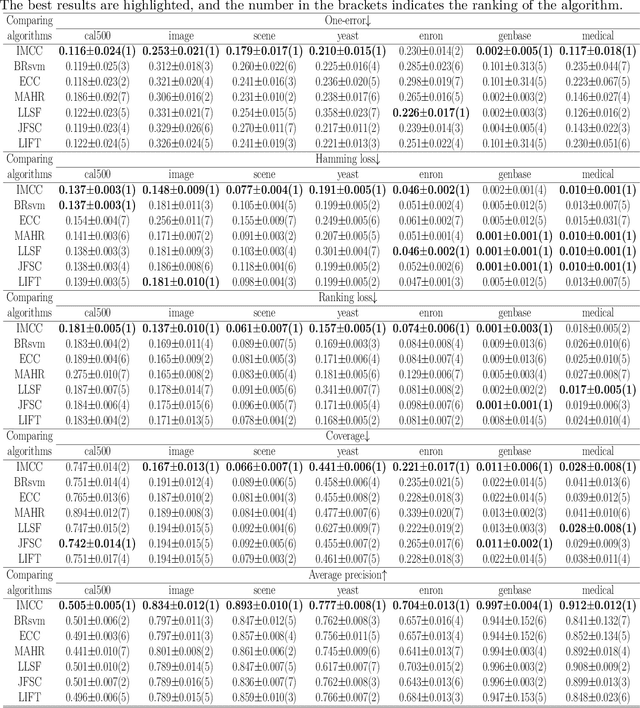
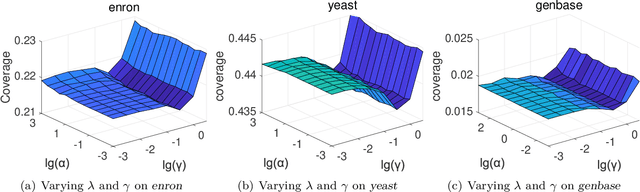
Multi-label learning deals with the problem that each instance is associated with multiple labels simultaneously. Most of the existing approaches aim to improve the performance of multi-label learning by exploiting label correlations. Although the data augmentation technique is widely used in many machine learning tasks, it is still unclear whether data augmentation is helpful to multi-label learning. In this paper, (to the best of our knowledge) we provide the first attempt to leverage the data augmentation technique to improve the performance of multi-label learning. Specifically, we first propose a novel data augmentation approach that performs clustering on the real examples and treats the cluster centers as virtual examples, and these virtual examples naturally embody the local label correlations and label importances. Then, motivated by the cluster assumption that examples in the same cluster should have the same label, we propose a novel regularization term to bridge the gap between the real examples and virtual examples, which can promote the local smoothness of the learning function. Extensive experimental results on a number of real-world multi-label data sets clearly demonstrate that our proposed approach outperforms the state-of-the-art counterparts.