 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware Gradient Algorithms for Neural Architecture Search
Paper and Code
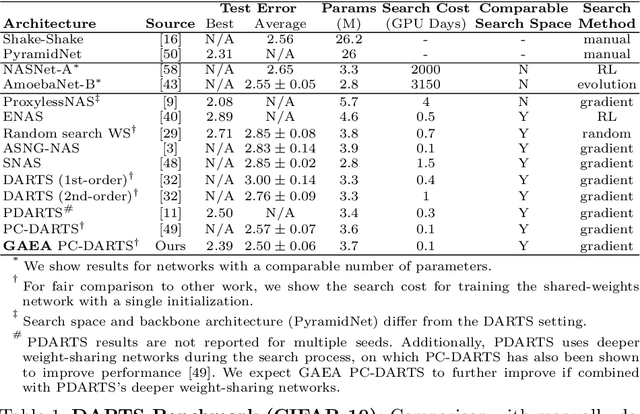
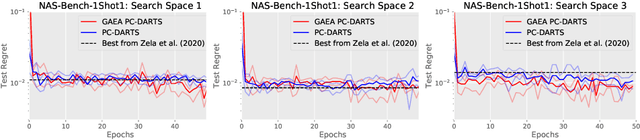
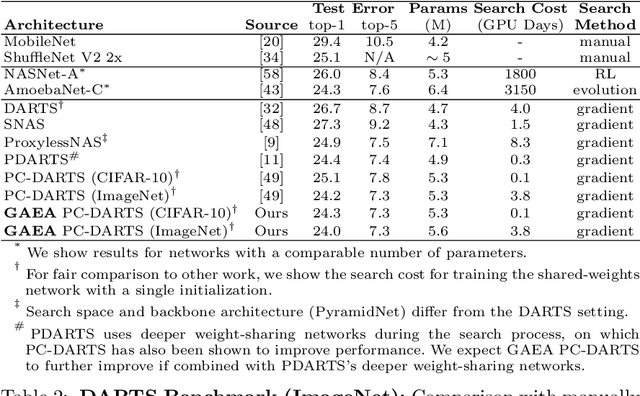
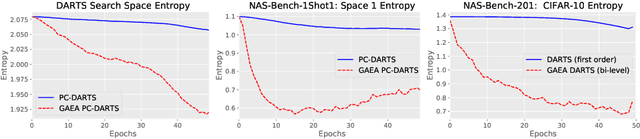
Many recent state-of-the-art methods for neural architecture search (NAS) relax the NAS problem into a joint continuous optimization over architecture parameters and their shared-weights, enabling the application of standard gradient-based optimizers. However, this training process remains poorly understood, as evidenced by the multitude of gradient-based heuristics that have been recently proposed. Invoking the theory of mirror descent, we present a unifying framework for designing and analyzing gradient-based NAS methods that exploit the underlying problem structure to quickly find high-performance architectures. Our geometry-aware framework leads to simple yet novel algorithms that (1) enjoy faster convergence guarantees than existing gradient-based methods and (2) achieve state-of-the-art accuracy on the latest NAS benchmarks in computer vision. Notably, we exceed the best published results for both CIFAR and ImageNet on both the DARTS search space and NAS-Bench-201; on the latter benchmark we achieve close to oracle-optimal performance on CIFAR-10 and CIFAR-100. Together, our theory and experiments demonstrate a principled way to co-design optimizers and continuous parameterizations of discrete NAS search spaces.