 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Effects of Random Walk Based Minibatch Selection Policy on Knowledge Graph Completion
Paper and Code
Apr 12, 2020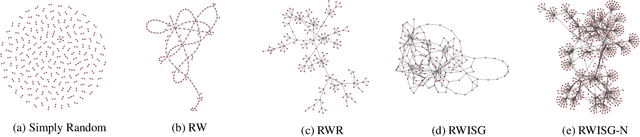
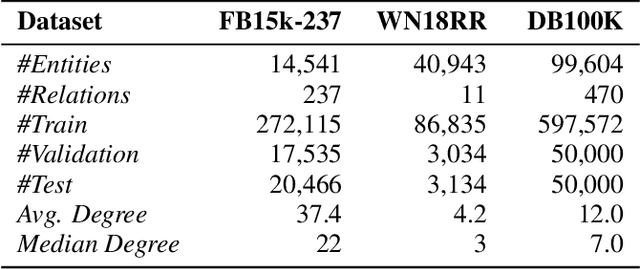
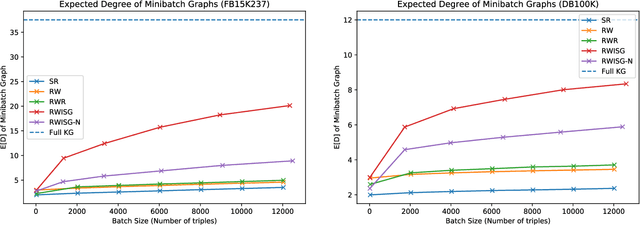
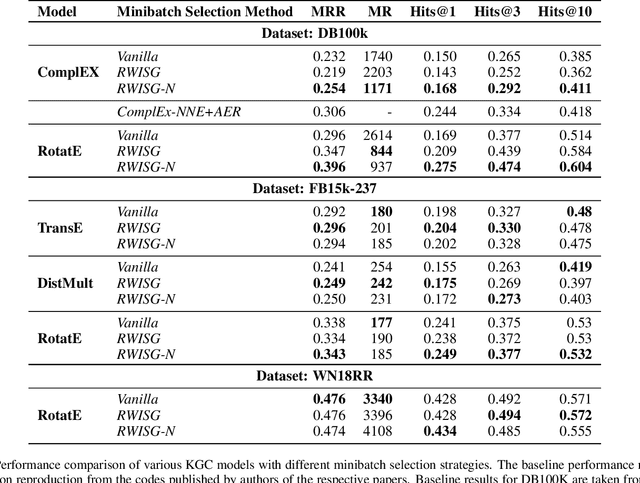
In this paper, we have explored the effects of different minibatch sampling techniques in Knowledge Graph Completion. Knowledge Graph Completion (KGC) or Link Prediction is the task of predicting missing facts in a knowledge graph. KGC models are usually trained using margin, soft-margin or cross-entropy loss function that promotes assigning a higher score or probability for true fact triplets. Minibatch gradient descent is used to optimize these loss functions for training the KGC models. But, as each minibatch consists of only a few randomly sampled triplets from a large knowledge graph, any entity that occurs in a minibatch, occurs only once in most cases. Because of this, these loss functions ignore all other neighbors of any entity, whose embedding is being updated at some minibatch step. In this paper, we propose a new random-walk based minibatch sampling technique for training KGC models that optimizes the loss incurred by a minibatch of closely connected subgraph of triplets instead of randomly selected ones. We have shown results of experiments for different models and datasets with our sampling technique and found that the proposed sampling algorithm has varying effects on these datasets/models. Specifically, we find that our proposed method achieves state-of-the-art performance on the DB100K dataset.