 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Evaluating the Robustness of Chinese BERT Classifiers
Paper and Code
Apr 07, 2020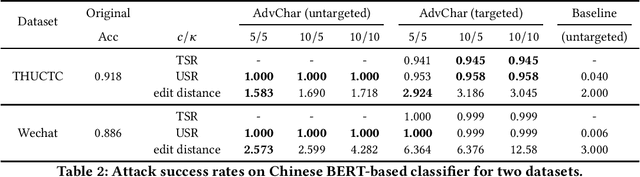


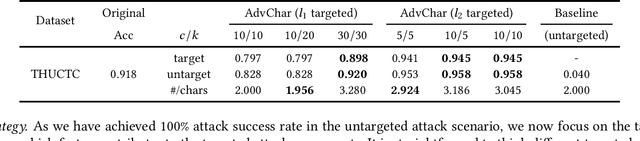
Recent advances in large-scale language representation models such as BERT have improved the state-of-the-art performances in many NLP tasks. Meanwhile, character-level Chinese NLP models, including BERT for Chinese, have also demonstrated that they can outperform the existing models. In this paper, we show that, however, such BERT-based models are vulnerable under character-level adversarial attacks. We propose a novel Chinese char-level attack method against BERT-based classifiers. Essentially, we generate "small" perturbation on the character level in the embedding space and guide the character substitution procedure. Extensive experiments show that the classification accuracy on a Chinese news dataset drops from 91.8% to 0% by manipulating less than 2 characters on average based on the proposed attack. Human evaluations also confirm that our generated Chinese adversarial examples barely affect human performance on these NLP tasks.