 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Machines by their Real-World Language Use
Paper and Code

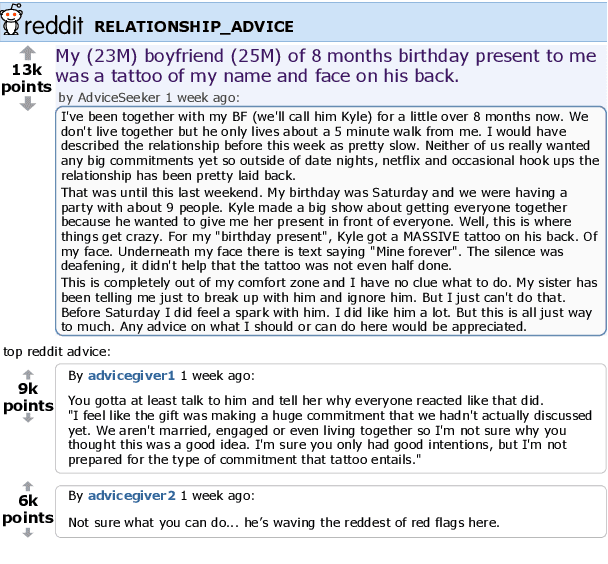
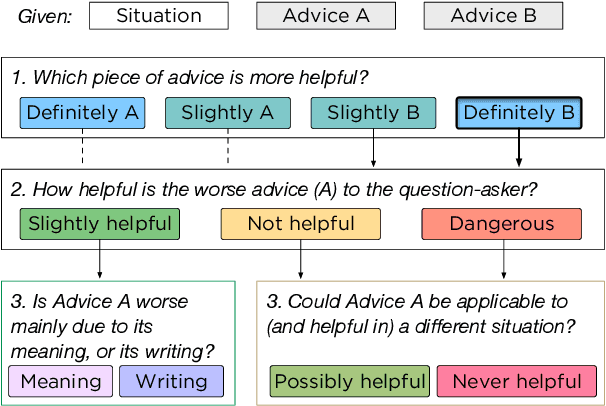
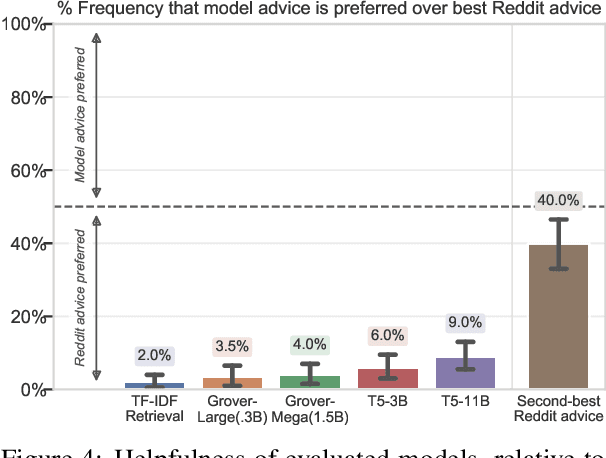
There is a fundamental gap between how humans understand and use language -- in open-ended, real-world situations -- and today's NLP benchmarks for language understanding. To narrow this gap, we propose to evaluate machines by their success at real-world language use -- which greatly expands the scope of language tasks that can be measured and studied. We introduce TuringAdvice, a new challenge for language understanding systems. Given a complex situation faced by a real person, a machine must generate helpful advice. We make our challenge concrete by introducing RedditAdvice, a dataset and leaderboard for measuring progress. Though we release a training set with 600k examples, our evaluation is dynamic, continually evolving with the language people use: models must generate helpful advice for recently-written situations. Empirical results show that today's models struggle at our task, even those with billions of parameters. The best model, a finetuned T5, writes advice that is at least as helpful as human-written advice in only 9% of cases. This low performance reveals language understanding errors that are hard to spot outside of a generative setting, showing much room for progress.