 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Short-Term Relation Networks for Video Action Detection
Paper and Code
Mar 31, 2020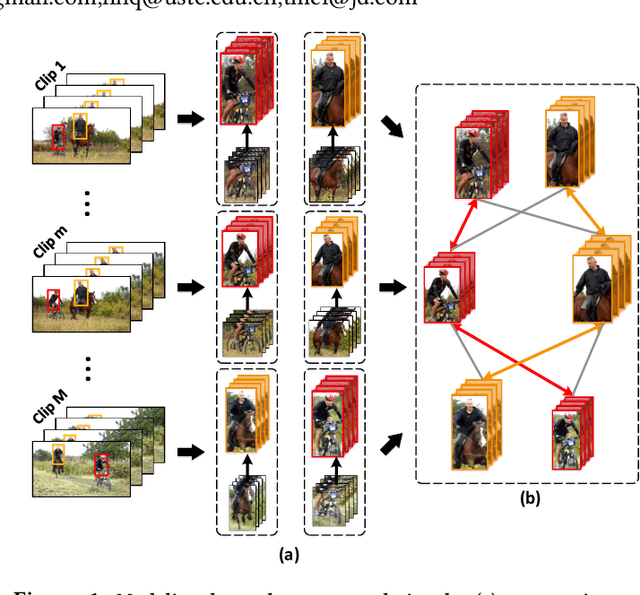
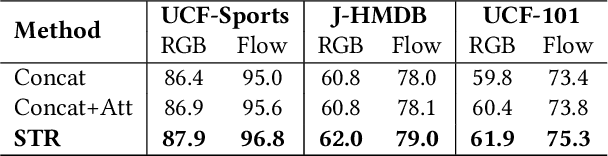
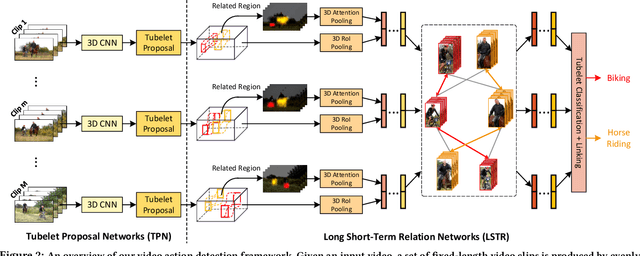
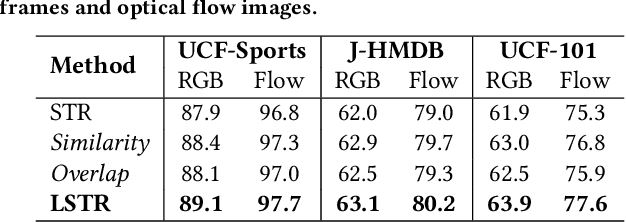
It has been well recognized that modeling human-object or object-object relations would be helpful for detection task. Nevertheless, the problem is not trivial especially when exploring the interactions between human actor, object and scene (collectively as human-context) to boost video action detectors. The difficulty originates from the aspect that reliable relations in a video should depend on not only short-term human-context relation in the present clip but also the temporal dynamics distilled over a long-range span of the video. This motivates us to capture both short-term and long-term relations in a video. In this paper, we present a new Long Short-Term Relation Networks, dubbed as LSTR, that novelly aggregates and propagates relation to augment features for video action detection. Technically, Region Proposal Networks (RPN) is remoulded to first produce 3D bounding boxes, i.e., tubelets, in each video clip. LSTR then models short-term human-context interactions within each clip through spatio-temporal attention mechanism and reasons long-term temporal dynamics across video clips via Graph Convolutional Networks (GCN) in a cascaded manner. Extensive experiments are conducted on four benchmark datasets, and superior results are reported when comparing to state-of-the-art methods.