 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically Multi-modal Image Synthesis
Paper and Code

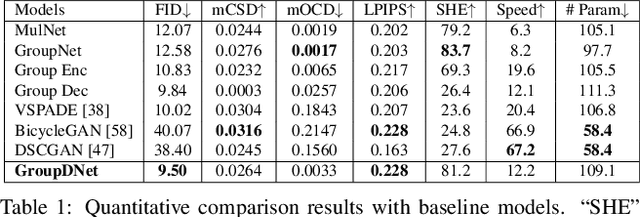
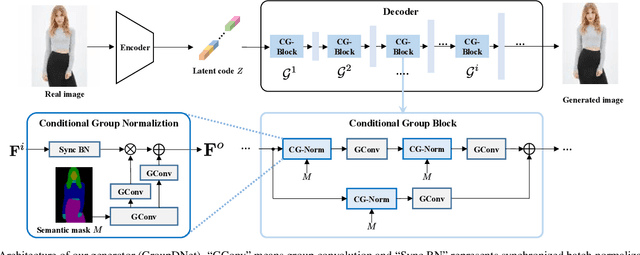
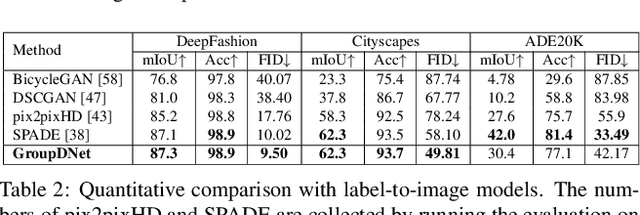
In this paper, we focus on semantically multi-modal image synthesis (SMIS) task, namely, generating multi-modal images at the semantic level. Previous work seeks to use multiple class-specific generators, constraining its usage in datasets with a small number of classes. We instead propose a novel Group Decreasing Network (GroupDNet) that leverages group convolutions in the generator and progressively decreases the group numbers of the convolutions in the decoder. Consequently, GroupDNet is armed with much more controllability on translating semantic labels to natural images and has plausible high-quality yields for datasets with many classes. Experiments on several challenging datasets demonstrate the superiority of GroupDNet on performing the SMIS task. We also show that GroupDNet is capable of performing a wide range of interesting synthesis applications. Codes and models are available at: https://github.com/Seanseattle/SMIS.