 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTH: Spatio-Temporal Hybrid Convolution for Efficient Action Recognition
Paper and Code
Mar 18, 2020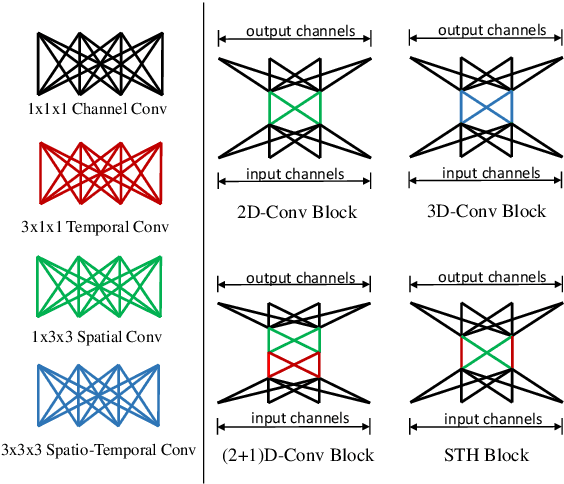
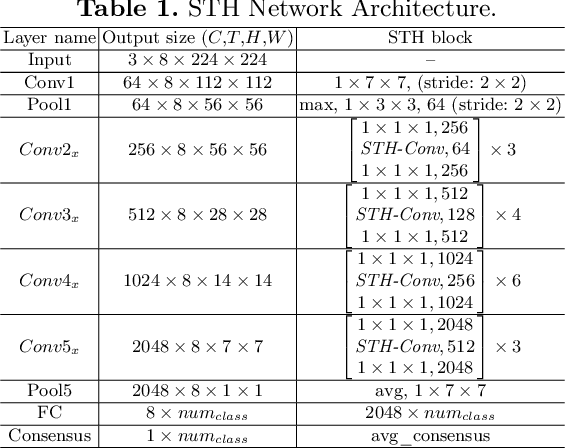
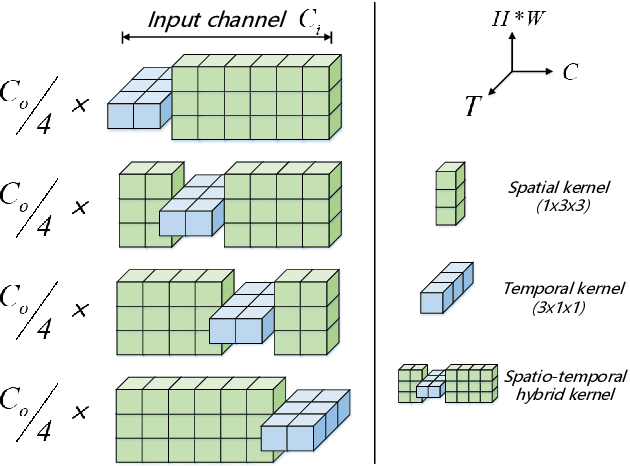
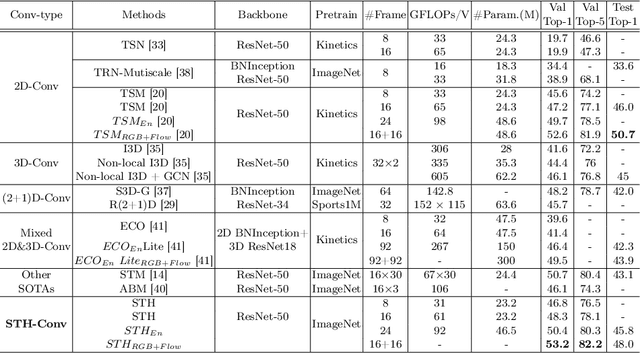
Effective and Efficient spatio-temporal modeling is essential for action recognition. Existing methods suffer from the trade-off between model performance and model complexity. In this paper, we present a novel Spatio-Temporal Hybrid Convolution Network (denoted as "STH") which simultaneously encodes spatial and temporal video information with a small parameter cost. Different from existing works that sequentially or parallelly extract spatial and temporal information with different convolutional layers, we divide the input channels into multiple groups and interleave the spatial and temporal operations in one convolutional layer, which deeply incorporates spatial and temporal clues. Such a design enables efficient spatio-temporal modeling and maintains a small model scale. STH-Conv is a general building block, which can be plugged into existing 2D CNN architectures such as ResNet and MobileNet by replacing the conventional 2D-Conv blocks (2D convolutions). STH network achieves competitive or even better performance than its competitors on benchmark datasets such as Something-Something (V1 & V2), Jester, and HMDB-51. Moreover, STH enjoys performance superiority over 3D CNNs while maintaining an even smaller parameter cost than 2D CNNs.