 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Distributed Deep Learning: A Comprehensive Survey
Paper and Code
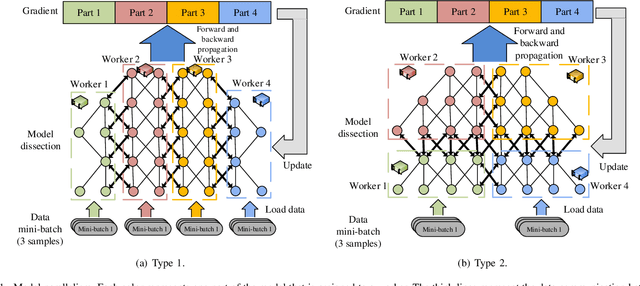
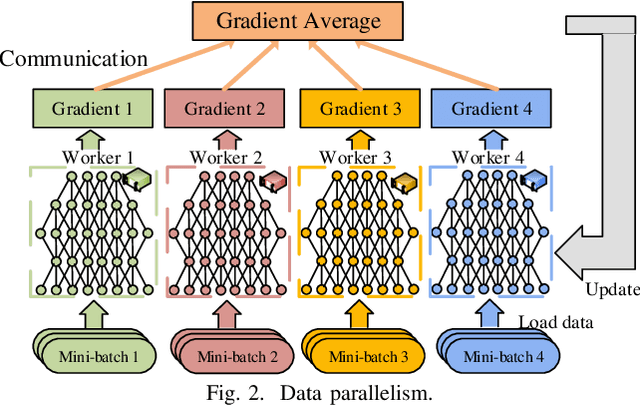
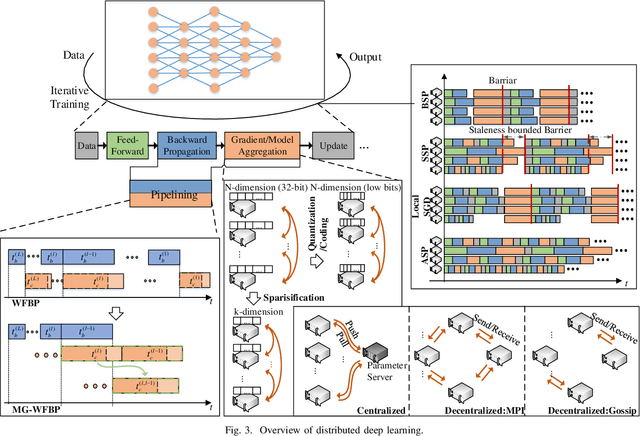
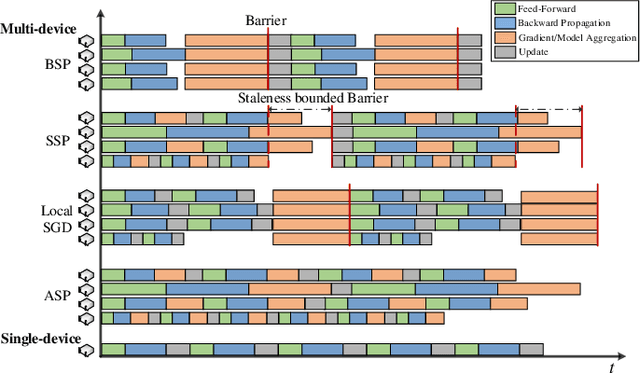
Distributed deep learning becomes very common to reduce the overall training time by exploiting multiple computing devices (e.g., GPUs/TPUs) as the size of deep models and data sets increases. However, data communication between computing devices could be a potential bottleneck to limit the system scalability. How to address the communication problem in distributed deep learning is becoming a hot research topic recently. In this paper, we provide a comprehensive survey of the communication-efficient distributed training algorithms in both system-level and algorithmic-level optimizations. In the system-level, we demystify the system design and implementation to reduce the communication cost. In algorithmic-level, we compare different algorithms with theoretical convergence bounds and communication complexity. Specifically, we first propose the taxonomy of data-parallel distributed training algorithms, which contains four main dimensions: communication synchronization, system architectures, compression techniques, and parallelism of communication and computing. Then we discuss the studies in addressing the problems of the four dimensions to compare the communication cost. We further compare the convergence rates of different algorithms, which enable us to know how fast the algorithms can converge to the solution in terms of iterations. According to the system-level communication cost analysis and theoretical convergence speed comparison, we provide the readers to understand what algorithms are more efficient under specific distributed environments and extrapolate potential directions for further optimizations.