 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Food Retrieval: Learning a Joint Embedding of Food Images and Recipes with Semantic Consistency and Attention Mechanism
Paper and Code
Mar 09, 2020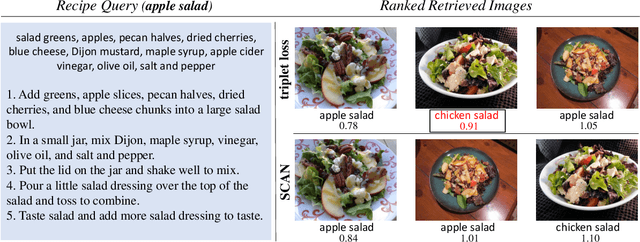
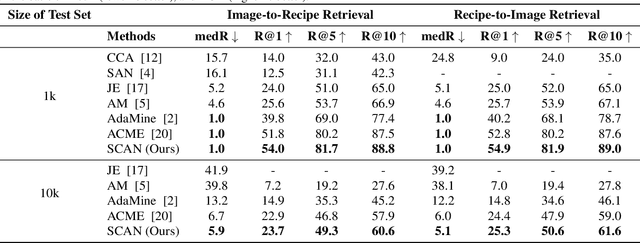
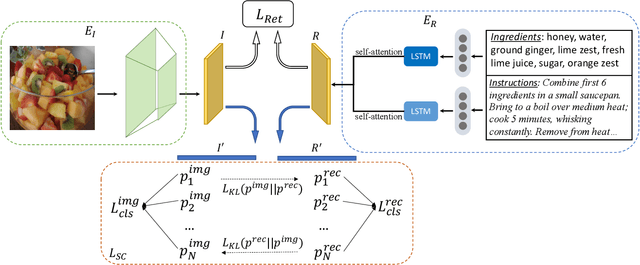
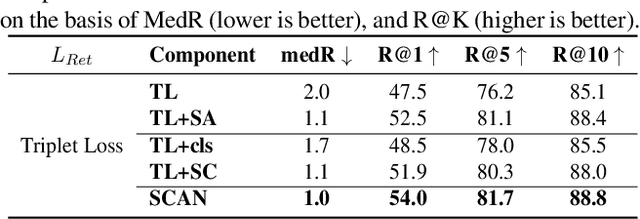
Cross-modal food retrieval is an important task to perform analysis of food-related information, such as food images and cooking recipes. The goal is to learn an embedding of images and recipes in a common feature space, so that precise matching can be realized. Compared with existing cross-modal retrieval approaches, two major challenges in this specific problem are: 1) the large intra-class variance across cross-modal food data; and 2) the difficulties in obtaining discriminative recipe representations. To address these problems, we propose Semantic-Consistent and Attention-based Networks (SCAN), which regularize the embeddings of the two modalities by aligning output semantic probabilities. In addition, we exploit self-attention mechanism to improve the embedding of recipes. We evaluate the performance of the proposed method on the large-scale Recipe1M dataset, and the result shows that it outperforms the state-of-the-art.