 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Embeddings Based On Self-Attention
Paper and Code
Mar 03, 2020
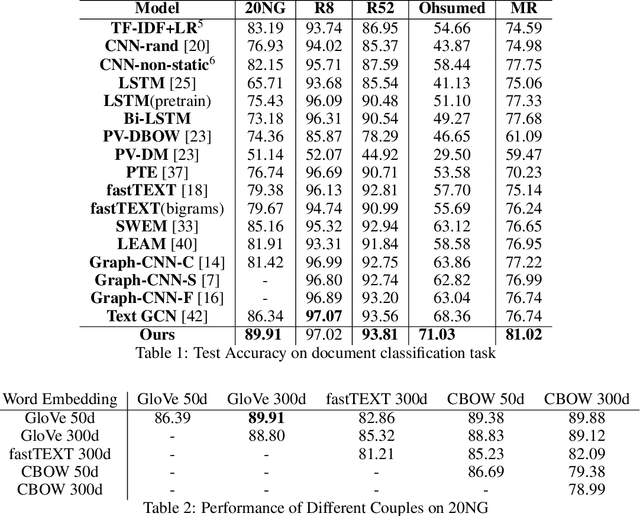
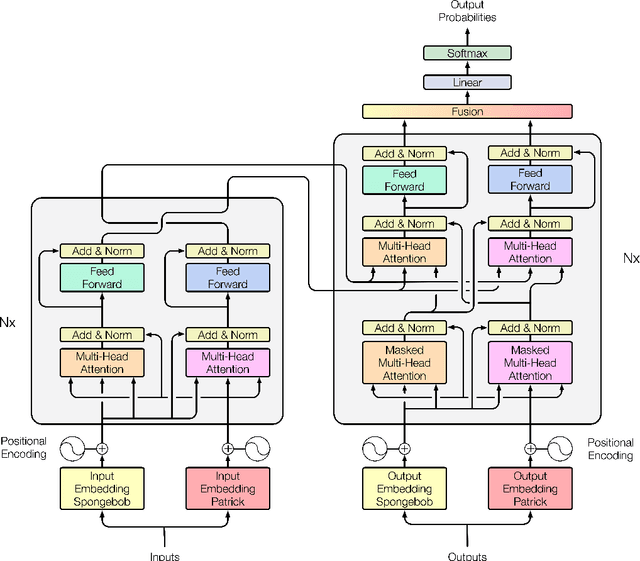
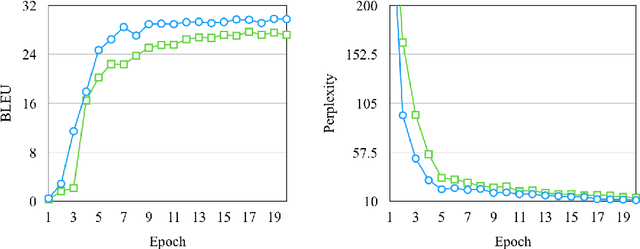
Creating meta-embeddings for better performance in language modelling has received attention lately, and methods based on concatenation or merely calculating the arithmetic mean of more than one separately trained embeddings to perform meta-embeddings have shown to be beneficial. In this paper, we devise a new meta-embedding model based on the self-attention mechanism, namely the Duo. With less than 0.4M parameters, the Duo mechanism achieves state-of-the-art accuracy in text classification tasks such as 20NG. Additionally, we propose a new meta-embedding sequece-to-sequence model for machine translation, which to the best of our knowledge, is the first machine translation model based on more than one word-embedding. Furthermore, it has turned out that our model outperform the Transformer not only in terms of achieving a better result, but also a faster convergence on recognized benchmarks, such as the WMT 2014 English-to-French translation task.