 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCautious Reinforcement Learning via Distributional Risk in the Dual Domain
Paper and Code
Feb 27, 2020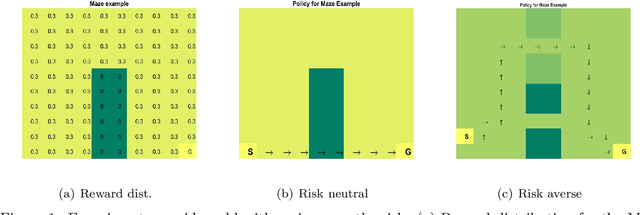
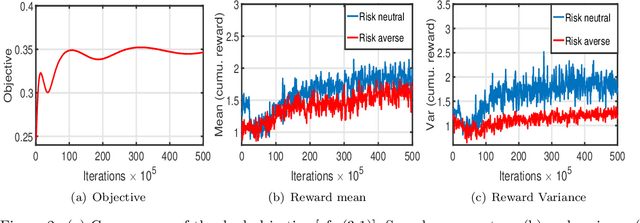
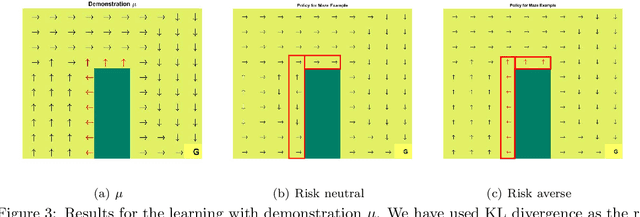
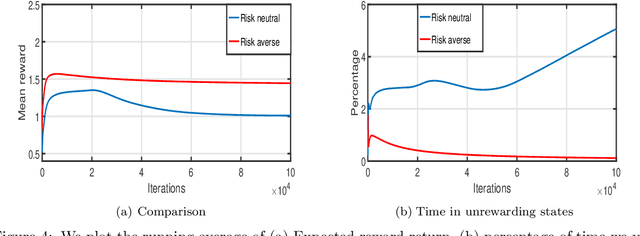
We study the estimation of risk-sensitive policies in reinforcement learning problems defined by a Markov Decision Process (MDPs) whose state and action spaces are countably finite. Prior efforts are predominately afflicted by computational challenges associated with the fact that risk-sensitive MDPs are time-inconsistent. To ameliorate this issue, we propose a new definition of risk, which we call caution, as a penalty function added to the dual objective of the linear programming (LP) formulation of reinforcement learning. The caution measures the distributional risk of a policy, which is a function of the policy's long-term state occupancy distribution. To solve this problem in an online model-free manner, we propose a stochastic variant of primal-dual method that uses Kullback-Lieber (KL) divergence as its proximal term. We establish that the number of iterations/samples required to attain approximately optimal solutions of this scheme matches tight dependencies on the cardinality of the state and action spaces, but differs in its dependence on the infinity norm of the gradient of the risk measure. Experiments demonstrate the merits of this approach for improving the reliability of reward accumulation without additional computational burdens.