 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech2Phone: A Multilingual and Text Independent Speaker Identification Model
Paper and Code

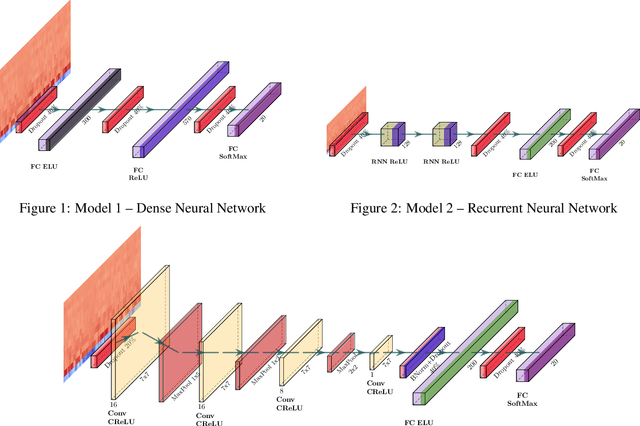
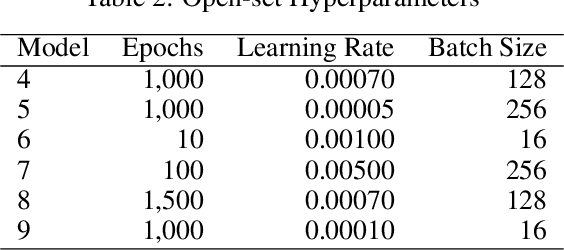
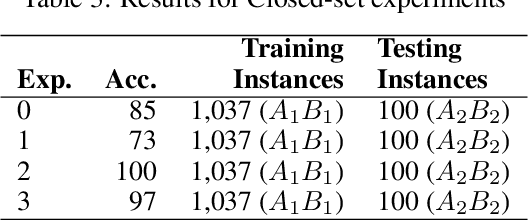
Voice recognition is an area with a wide application potential. Speaker identification is useful in several voice recognition tasks, as seen in voice-based authentication, transcription systems and intelligent personal assistants. Some tasks benefit from open-set models which can handle new speakers without the need of retraining. Audio embeddings for speaker identification is a proposal to solve this issue. However, choosing a suitable model is a difficult task, especially when the training resources are scarce. Besides, it is not always clear whether embeddings are as good as more traditional methods. In this work, we propose the Speech2Phone and compare several embedding models for open-set speaker identification, as well as traditional closed-set models. The models were investigated in the scenario of small datasets, which makes them more applicable to languages in which data scarceness is an issue. The results show that embeddings generated by artificial neural networks are competitive when compared to classical approaches for the task. Considering a testing dataset composed of 20 speakers, the best models reach accuracies of 100% and 76.96% for closed an open set scenarios, respectively. Results suggest that the models can perform language independent speaker identification. Among the tested models, a fully connected one, here presented as Speech2Phone, led to the higher accuracy. Furthermore, the models were tested for different languages showing that the knowledge learned was successfully transferred for close and distant languages to Portuguese (in terms of vocabulary). Finally, the models can scale and can handle more speakers than they were trained for, identifying 150% more speakers while still maintaining 55% accuracy.