 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Transform and Metric Learning Network: Wedding Deep Dictionary Learning and Neural Networks
Paper and Code
Feb 18, 2020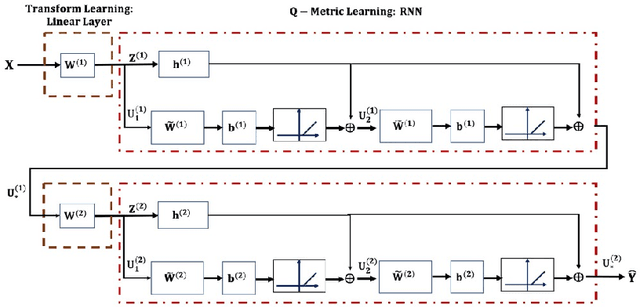
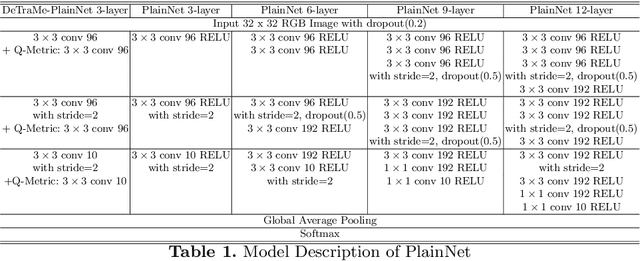
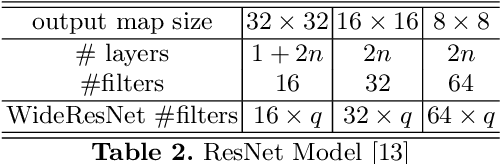
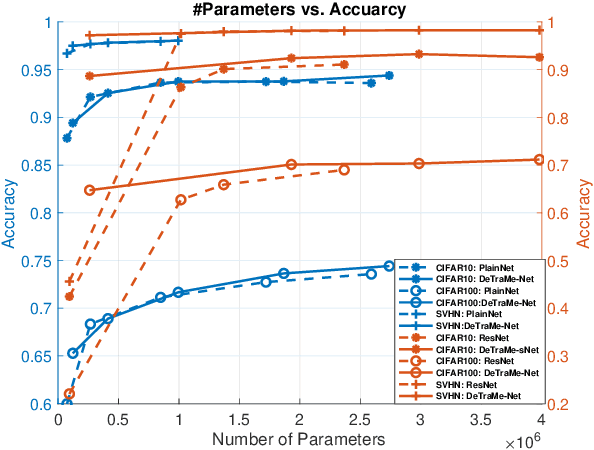
On account of its many successes in inference tasks and denoising applications, Dictionary Learning (DL) and its related sparse optimization problems have garnered a lot of research interest. While most solutions have focused on single layer dictionaries, the improved recently proposed Deep DL (DDL) methods have also fallen short on a number of issues. We propose herein, a novel DDL approach where each DL layer can be formulated as a combination of one linear layer and a Recurrent Neural Network (RNN). The RNN is shown to flexibly account for the layer-associated and learned metric. Our proposed work unveils new insights into Neural Networks and DDL and provides a new, efficient and competitive approach to jointly learn a deep transform and a metric for inference applications. Extensive experiments are carried out to demonstrate that the proposed method can not only outperform existing DDL but also state-of-the-art generic CNNs.