 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehensive and Efficient Data Labeling via Adaptive Model Scheduling
Paper and Code
Feb 08, 2020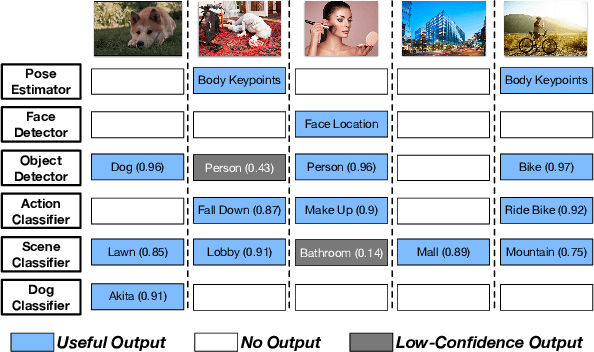
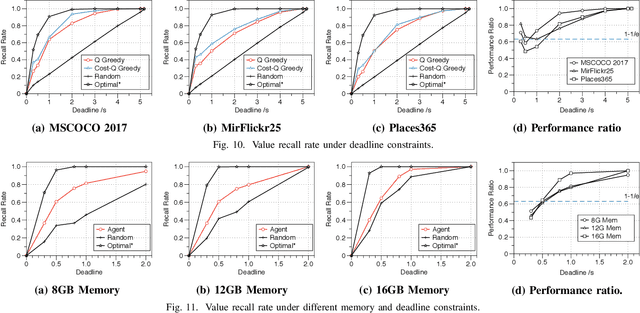
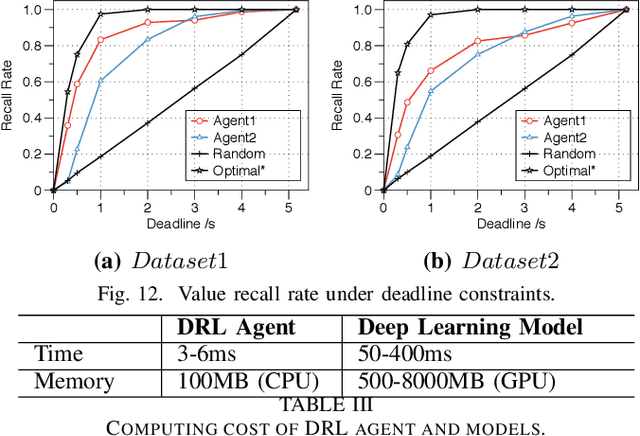
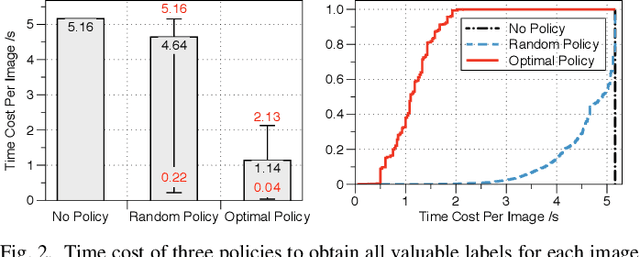
Labeling data (e.g., labeling the people, objects, actions and scene in images) comprehensively and efficiently is a widely needed but challenging task. Numerous models were proposed to label various data and many approaches were designed to enhance the ability of deep learning models or accelerate them. Unfortunately, a single machine-learning model is not powerful enough to extract various semantic information from data. Given certain applications, such as image retrieval platforms and photo album management apps, it is often required to execute a collection of models to obtain sufficient labels. With limited computing resources and stringent delay, given a data stream and a collection of applicable resource-hungry deep-learning models, we design a novel approach to adaptively schedule a subset of these models to execute on each data item, aiming to maximize the value of the model output (e.g., the number of high-confidence labels). Achieving this lofty goal is nontrivial since a model's output on any data item is content-dependent and unknown until we execute it. To tackle this, we propose an Adaptive Model Scheduling framework, consisting of 1) a deep reinforcement learning-based approach to predict the value of unexecuted models by mining semantic relationship among diverse models, and 2) two heuristic algorithms to adaptively schedule the model execution order under a deadline or deadline-memory constraints respectively. The proposed framework doesn't require any prior knowledge of the data, which works as a powerful complement to existing model optimization technologies. We conduct extensive evaluations on five diverse image datasets and 30 popular image labeling models to demonstrate the effectiveness of our design: our design could save around 53\% execution time without loss of any valuable labels.