 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Autotuner: a Pitch Correcting Network for Singing Performances
Paper and Code
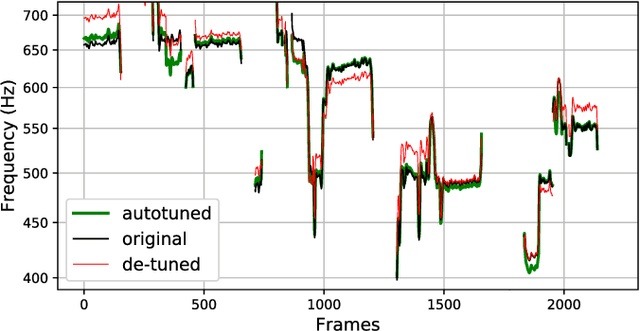
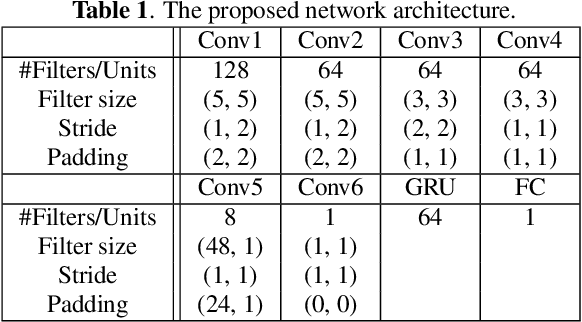
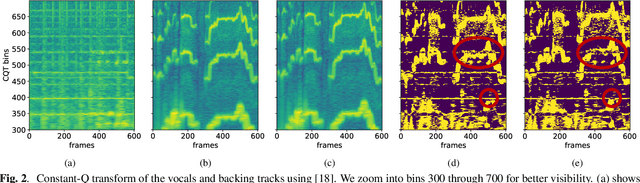
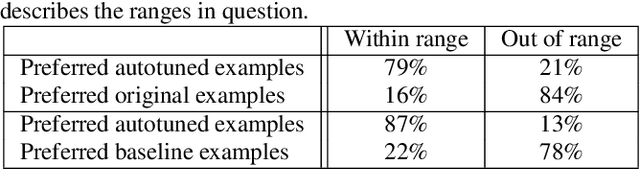
We introduce a data-driven approach to automatic pitch correction of solo singing performances. The proposed approach predicts note-wise pitch shifts from the relationship between the respective spectrograms of the singing and accompaniment. This approach differs from commercial systems, where vocal track notes are usually shifted to be centered around pitches in a user-defined score, or mapped to the closest pitch among the twelve equal-tempered scale degrees. The proposed system treats pitch as a continuous value rather than relying on a set of discretized notes found in musical scores, thus allowing for improvisation and harmonization in the singing performance. We train our neural network model using a dataset of 4,702 amateur karaoke performances selected for good intonation. Our model is trained on both incorrect intonation, for which it learns a correction, and intentional pitch variation, which it learns to preserve. The proposed deep neural network with gated recurrent units on top of convolutional layers shows promising performance on the real-world score-free singing pitch correction task of autotuning.